
Spotlight
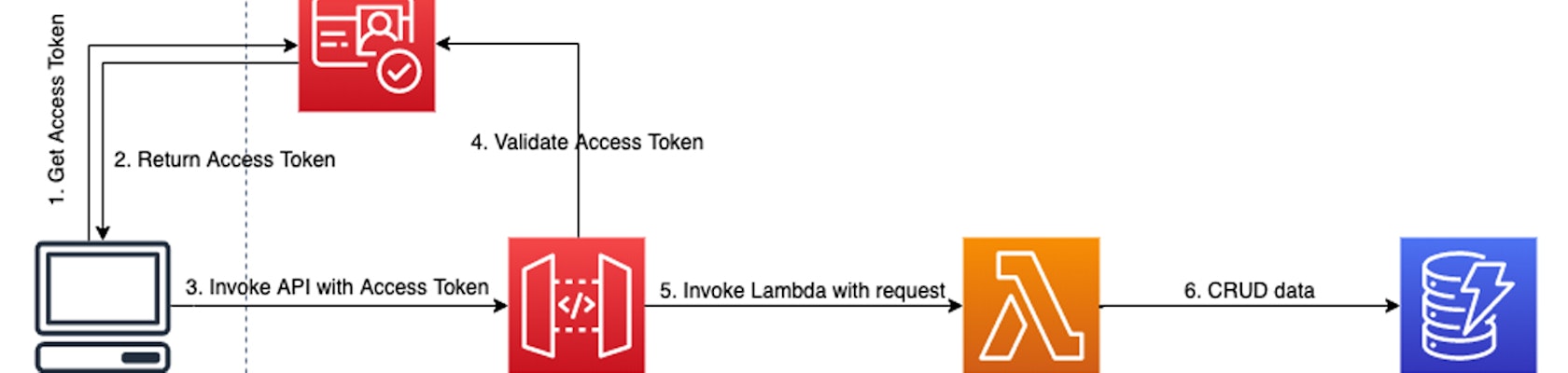
AWS Lambda Functions: Return Response and Continue Executing
A how-to guide using the Node.js Lambda runtime.

This week, AWS open-sourced an application that doesn't appear, on first glance, to have much practical use: it's a stripped down implementation of their Serverless Application Repository service, effectively a static website with a CRUD backend. Probably not something you've been longing to deploy in your environment.The app itself isn't the point in this case, of course, except insofar as it reflects a real-world production service and not a contrived example. The real value here is in seeing more or less how AWS lays out the code and config for a serverless app that they deploy and operate in production.
You can read their blog post and go through the repository wiki for a blow-by-blow explanation of how this is all put together, and I recommend that you do. Here, I want to note a few elements that stood out to me.
Each "component" of the application (backend, frontend, async analytics pipeline, monitoring) gets its own subfolder, its own SAM template, its own CI/CD, its own unit tests. There's also a top level template that nests everything beneath it.The upside to this approach: WAY more control over how you manage releases. Deploy the top-level stack and spit out your whole application with all the components in the correct order, no worries about dependencies. Roll out an update to an individual stack and you move fast without breaking (too many) things.
You have to dig in a bit to find them, but possibly the most useful elements of this project aren't even in the repo: they were published as separate SAR applications for CI (a CodeBuild project for unit tests, integrating with your GitHub repo) and CD (a CodePipeline with build - > test -> deploy stages). Plug-and-play CI/CD? Yes please.The interesting choice here is to hold the IAM roles out of the SAR apps: in other words, there's no global admin "CD" role with absolute deployment rights. Instead, AWS makes the safer but much more labor-intensive choice to pass a role with every single component containing the (usually quite extensive) list of permissions needed to deploy that component successfully. This is one place where other shops will find it challenging to follow in AWS's footsteps.
The repo wiki contains a lovely, opinionated set of CloudFormation best practices and makes a great case for using nested stacks, something we're also a fan of at Trek10. Technically, though, this app doesn't use nested CloudFormation stacks, but nested SAR apps. Same idea, with the added benefit of publishing those apps internally for greater discoverability. Your mileage may vary on whether you think of your app components as worth publishing to SAR individually. In this case, it's probably overkill. Can't blame the Serverless App Repo team for modeling usage of their own service though!
The only parameter you can specify at deploy time -- aside from a Github token for CI/CD that has to be seeded in Secrets Manager -- is the stage descriptor that takes care of namespacing for your stack. Everything else is either dynamically generated (no hardcoded S3 bucket or DynamoDB table names here) or shared between the nested stacks via SSM Parameter Store, as Trek10's Ryan Scott Brown recently recommended. That even extends to Lambda functions, which pull their parameters from SSM rather than using environment variables.
The no-environment-variables strategy does require an in-function caching solution to keep from overwhelming Parameter Store's limited throughput, and I'm not sure I understand how it would scale during bursty load. I get the sense it may be inspired more by tradeoffs like Lambda environment variables not being available in all regions, and I think for non-sensitive parameters you should still consider putting them in environment variables where you can.
Any configuration local to a stack, such as the DynamoDB billing model, is hardcoded in the SAM template. This works fine unless you expect your service to use different configuration in different environments, which left me disappointed that ...
All the ingredients are here for a true productionized service: there's an "ops" stack with some CloudWatch metrics and dashboards, you have pipelines to push out your code ... as long as you keep it in the same AWS environment. There's no concept of a multi-account pipeline, code promotion, etc. I was also disappointed to see that there are no end-to-end tests run on the deployed code as part of the pipeline. I'm sure these things exist in AWS's actual Serverless App Repo service, but evidently this is where they had to stop in order to come up with something of reasonable example size.
No secret sauce here, really. AWS is doing all the things they've been telling us to do for years. The Serverless App Repo is probably overused to no obvious purpose (though Aleksandr Simovic's "Deploy to S3" SAR app comes in handy for the static website piece), but overall it's encouraging to note that serverless does not require some magic formula: AWS uses the same services in mostly the same way that their customers do.
The hard parts, as always, are in the details: the IAM permissions, the parameter hygiene, the cold start mitigation. This repo gives you a great blueprint for overcoming those challenges, but it's up to you to execute.

A how-to guide using the Node.js Lambda runtime.






