

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


Having been primarily worked with NodeJs for the past few years, whenever I'm working on a serverless Python project one thing I miss is the ease with which NodeJs allows for parallelizing API calls to AWS. You can just
let promises = listOfS3Keys.forEach(keys => s3.getObjectAcl({
Bucket: 'yourBucket',
Key: key,
}).promise());
await Promise.all(promises);
Parallelism while not quite as easy in Python is still possible with a few lines of code.
In Python 2.x and in early versions of Python 3 the most straightforward way to a parallelize is using threads. While possible it adds complexity to your code that can be avoided now.
Python 3.4 introduced the async and await keywords and the asyncio library that can help parallelize network IO operations.
To use async/await in Python you ideally should use non-blocking IO requests. Unfortunately, boto3 uses blocking IO requests. Fortunately, there is a library aioboto3 that aims to be drop in compatible with boto3 but uses async/non-blocking IO requests to make API calls. Now you can also use boto3 if you run it in a thread executor (e.g. loop.run_in_executor)
I decided to do a comparison of the performance and complexity of using aioboto3 or boto3 along with asyncio for parallelizing API calls. To get a baseline I also created a function that made the same API calls in series (i.e. without parallelism)
The code in each function lists all the objects in an S3 Bucket and then calls get_object_acl for each key. There were 100 objects in the bucket.
Serial boto3 function code
import os
import boto3
s3 = boto3.client('s3')
BUCKET_NAME = os.getenv('BUCKET_NAME')
def main():
bucket_contents = s3.list_objects_v2(Bucket=BUCKET_NAME)
objects = [
s3.get_object_acl(Bucket=BUCKET_NAME, Key=content_entry['Key'])
for content_entry in bucket_contents['Contents']
]
def handler(event, context):
return main()
Parallelized boto3 with asyncio function code
import asyncio
import functools
import os
import boto3
BUCKET_NAME = os.getenv('BUCKET_NAME')
s3 = boto3.client('s3')
async def main():
loop = asyncio.get_running_loop()
bucket_contents = s3.list_objects_v2(Bucket=BUCKET_NAME)
objects = await asyncio.gather(
*[
loop.run_in_executor(None, functools.partial(s3.get_object_acl, Bucket=BUCKET_NAME, Key=content_entry['Key']))
for content_entry in bucket_contents['Contents']
]
)
def handler(event, context):
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
Parallelized aioboto3 with asyncio function code
import asyncio
import os
import aioboto3
BUCKET_NAME = os.getenv('BUCKET_NAME')
async def main():
async with aioboto3.client('s3') as s3:
bucket_contents = await s3.list_objects_v2(Bucket=BUCKET_NAME)
objects = await asyncio.gather(
*[
s3.get_object_acl(Bucket=BUCKET_NAME, Key=content_entry['Key'])
for content_entry in bucket_contents['Contents']
]
)
def handler(event, context):
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
I ran each function in a Python 3.8.x Lambda Function. I also used different memory sizes to see how much that affected the execution time. I ran each function 100 times and recorded the average run time as reported by the REPORT log entry in the CloudWatch logs. The following graph and table show the average function duration across the runs.
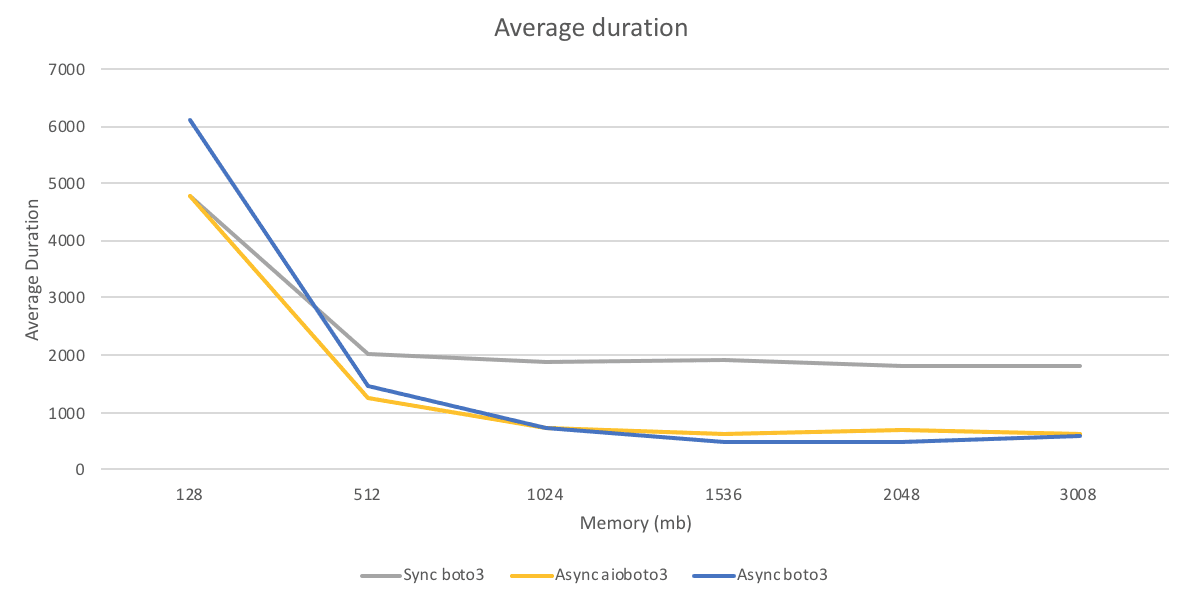
| Memory (mb) | Sync boto3 | Async aioboto3 | Async boto3 |
|---|---|---|---|
| 128 | 4771.45 | 4792.22 | 6097.20 |
| 512 | 2020.62 | 1259.93 | 1446.13 |
| 1024 | 1888.41 | 734.59 | 707.98 |
| 1536 | 1921.05 | 615.03 | 486.31 |
| 2048 | 1824.93 | 682.80 | 483.95 |
| 3008 | 1799.03 | 616.14 | 572.16 |
| Average execution time across 100 invocations. All times are in milliseconds. |
Surprisingly at low memory (128mb) sequential synchronous calls were faster than either async method. I suspect this was because there was less TLS overhead since Python keeps the connection to S3 open across multiple calls. At higher Lambda memory aioboto3 had no advantage over boto3.
The final results of my parallel processing in Python with AWS Lambda experiment: While there are many parameters that can affect the throughput of parallel API calls, this test shows that
boto3 is sufficient for basic parallelism and in some cases exceeds the performance of aioboto3.
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.





