

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


DynamoDB is one of the fastest-growing databases right now. It's fully-managed, has pay-per-use billing, and fits perfectly with serverless compute.
But modeling your data in DynamoDB is significantly different than modeling in a traditional relational database. And if you try to model your DynamoDB table like your relational database, you'll be in a world of hurt.
In this post, we're going to cover my top ten tips for data modeling with DynamoDB. They run the gamut, from understanding of basic principles to concrete design tips to billing advice. With these tips, you'll be on your way to DynamoDB success.
If you find yourself enjoying this content as you go, I'd really appreciate and encourage you to take a look at my new book on DynamoDB as well!
Let's get started!
By far, the biggest mindset shift you will make as you move from a traditional relational database into DynamoDB is the acceptance of "single-table design". In a relational database, each different entity will receive its own table, specifically shaped to hold that entity's data. There will be columns for each of the entity's attributes with required values and constraints.
With DynamoDB, this isn't the case. You'll jam all of your entities--Customers, Orders, Inventory, etc.--into a single table. There are no required columns and attributes, save for the primary key which uniquely identifies each item.
Your table will look more like the following:
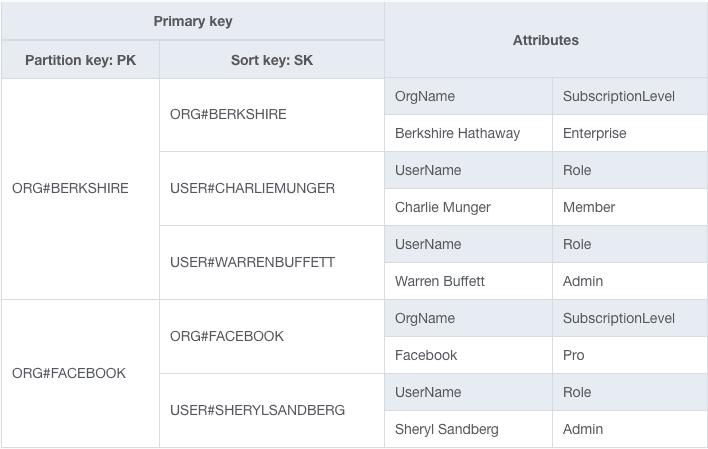
This may look like hieroglyphics if you're new to DynamoDB and NoSQL design, but don't avoid it.
Take some time to understand why you need single-table design in DynamoDB. Single-table design is about efficiently organizing your data in the shape needed by your access patterns to quickly and efficiently use your data.
You won't have the neat, tidy, spreadsheet-like data that you had with a relational database. In fact, your table will look "more like machine code than a simple spreadsheet". But you will have a database that will scale to massive levels without any performance degradation.
Quote text: "If you don't know where you are going, any road will get you there." (Lewis Carroll)
With single-table design, you design your table to handle your access patterns. This implies that you must know your access patterns before you design.
So many developers want to design their DynamoDB table before they know how they'll use it. But again, this is that relational database mindset creeping into your process. With a relational database, you design your tables first, then add the indexes and write the queries to get the data you need. With DynamoDB, you first ask how you want to access the data, then build the table to handle these patterns.
This requires thoughtful work upfront. It requires engaging with PMs and business analysts to fully understand your application. And while this seems like it slows you down, you'll be glad you've done the work when you don't have to think about scaling your database when your application grows.
As developers, it's hard not to jump straight into the code. There's nothing quite like the dopamine hit of making something from nothing; from saying, "Yes, I built that!"
But you need to resist that impulse in DynamoDB data modeling. Once you've outlined your access patterns, then take the time to model your DynamoDB table. This should be done outside of your code. You can use pen & paper, Microsoft Excel, or the NoSQL Workbench for Amazon DynamoDB.
As you model your code, you should be making two artifacts:
For an example, here's a completed entity chart for one of the examples from my book:
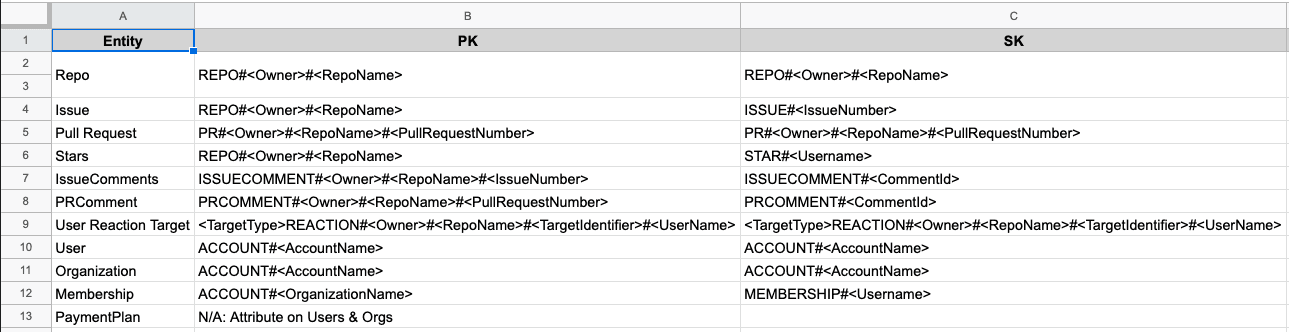
In this case, I just use a spreadsheet to list each entity type and the primary key pattern for each entity. I have additional pages for any secondary indexes in my table.
Once you complete these artifacts, then you can move into implementation. These artifacts will serve as great additions to your service documentation.
When learning relational data modeling, we heard all about normalization. Don't repeat data in multiple places. First normal form, second normal form, etc. As you normalize your data, you can join together multiple tables as query time to get your final answer.
Normalization was built for a world with very different assumptions. In the data centers of the 1980s, storage was at a premium and compute was relatively cheap. But the times have changed. Storage is cheap as can be, while compute is at a premium.
Relational patterns like joins and complex filters use up valuable compute resources. With DynamoDB, you optimize for the problems of today. That means conserving on compute by eschewing joins. Rather, you denormalize your data whether by duplicating data across multiple records or by storing related records directly on a parent record.
With denormalizing, data integrity is more of an application concern. You'll need to consider when this duplicated data can change and how to update it if needed. But this denormalization will give you a greater scale than is possible with other databases.
A common requirement in data modeling is that you have a property that is unique across your entire application. For example, you may not want two users to register with the same username, or you may want to prevent two orders with the same OrderId.
In DynamoDB, each record in a table is uniquely identified by the primary key for your table. You can use this primary key to ensure there is not an existing record with the same primary key. To do so, you would use a Condition Expression to prevent writing an item if an item with the same key already exists.
One additional caveat: you can only assert uniqueness on a single attribute with your primary key. If you try to assert uniqueness across two attributes by building both into a primary key, you will only ensure that no other item exists with the same combination of two attributes.
For example, imagine you require a username and an email address to create a user. In your application, you want to ensure no one else has the same username and that no other account has used the same email address. To handle this in DynamoDB, you would need to create two items in a transaction where each operation asserts that there is not an existing item with the same primary key.
If you use this pattern, your table will end up like the following:
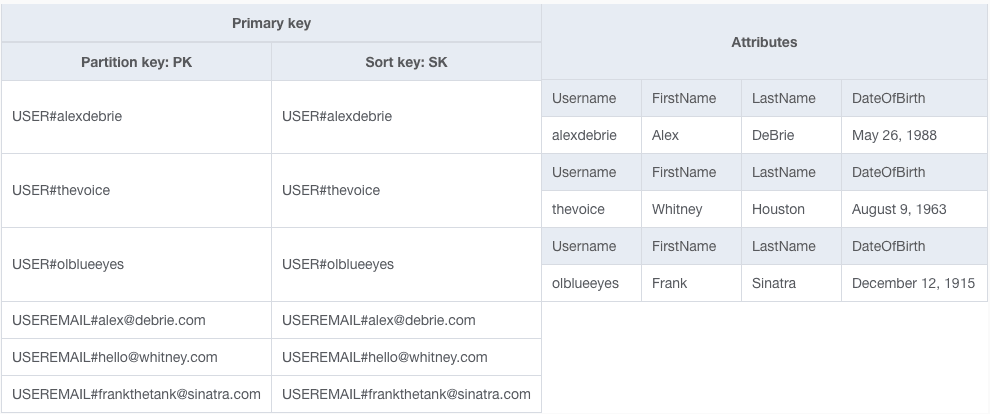
Like most NoSQL databases, DynamoDB partitions (or 'shards') your data by splitting it across multiple instances. Each instance holds only a subset of your data. This partitioning mechanism is what underlies the ability of NoSQL databases to scale further than SQL databases. If your data is all on one machine, you need to scale to larger and larger instance sizes with more RAM and CPU. You'll get decreasing returns on this scale, and eventually, you'll hit the limits of scaling on a single instance altogether.
To partition your data, DynamoDB uses the concept of a partition key. The partition key is part of your primary key and is used to indicate which instance should store that particular piece of data.
Even with this partitioning strategy, you need to be sure to avoid hot keys. A hot key is a partition key in your DynamoDB table that receives significantly more traffic than other keys in your table. This can happen if your data is highly skewed, such as the data has a Zipf distribution, or it can happen if you model your data incorrectly.
DynamoDB has done a ton of work to make hot keys less of an issue for you. This includes moving your total table capacity around to the keys that need it so it can better handle uneven distributions of your data.
The biggest concern you need to consider with hot keys is around partition limits. A single partition in DynamoDB cannot exceed 3,000 RCUs or 1,000 WCUs. Those are per second limits, so they go pretty high, but they are achievable if you have a high scale application.
When data modeling with DynamoDB, your primary key is paramount. It will be used to enforce uniqueness, as discussed above. It's also used to filter and query your data.
But you may have multiple, conflicting access patterns on a particular item in your table. One example I often use is a table that contains the roles played by actors and actresses in different movies. You may have one access pattern to fetch the roles by actor name, and another access pattern to fetch the roles in a particular movie.
Secondary indexes allow you to handle these additional access patterns. When you create a secondary index on your table, DynamoDB will handle copying all your data from your main table to the secondary index in a redesigned shape. In our movie roles example above, our main table may use the actor or actress's name as the partition key, while the secondary index could use the movie name as the partition key. This allows for handling both of our access patterns without requiring us to maintain two copies of the data ourselves.
Relationships between objects, whether one-to-many relationships or many-to-many relationships are common in data modeling. You'll have one entity (the 'parent') that has a number of related entities. Examples include customers to orders (a single customer will make multiple orders over time) or companies to employees (a single company will have many employees).
Often, you'll want to display the total count of related entities when showing the parent item. But for some relationships, this count can be quite large. Think of the number of stargazers for the React repository on GitHub(over 146,000) or the number of retweets on a particularly famous selfie from the Oscar's(over 3.1 million!).
When showing these counts, it's inefficient to count all the related records in your data each time to show the count. Rather, you should store these aggregates on the parent item as the related item is inserted.
There are two ways you can handle this. First, you can use DynamoDB Transactions to increment the count at the same time you create the related item. This is good to use when you have a large distribution of parent items and you want to ensure the related item doesn't already exist (e.g. that a given user hasn't starred this repo or retweeted this tweet before).
A second option is to use DynamoDB Streams. DynamoDB Streams allow you to turntable updates into an event stream allowing for asynchronous processing of your table. If you have a small number of items you're updating, you might want to use DynamoDB Streams to batch your increments and reduce the total number of writes to your table.
With DynamoDB, you can use multiple different attribute types, including strings, numbers, and maps.
One question I often get is around the best way to represent timestamps. Should you use an epoch timestamp, which is an integer representing the number of seconds passed since January 1, 1970, or should you use a human-readable string? What is the best DynamoDB date data type?
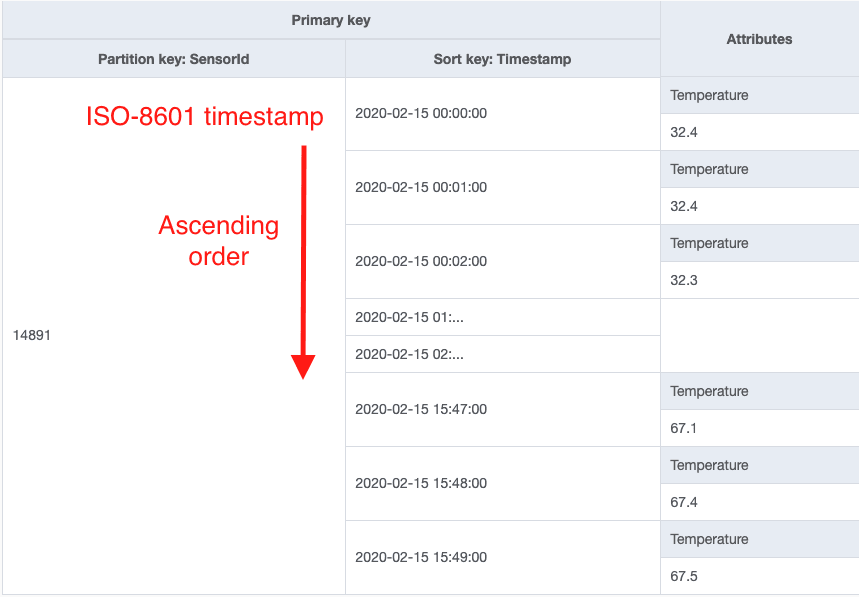
In most cases, I recommend using the ISO-8601 time format. This is a string-based representation of the time, such as 2020-04-06T20:18:29Z.
The benefits of the ISO-8601 format are two-fold. First, it is human-readable, which makes it easier to debug quickly in the AWS console. The ISO-8601 example above is much easier to parse than its corresponding epoch timestamp of 1586204309. Second, the ISO-8601 format is still sortable. If you're using a composite primary key, DynamoDB will sort all the items within a single partition in order of their UTF-8 bytes. The ISO-8601 format is designed to be sortable when moving from left-to-right, meaning you get readability without sacrificing sorting.
In the example below, we are storing sensor readings from an IoT device. The partition key is the SensorId, and the sort key is the ISO-8601 timestamp for the reading:
Now with this in mind, there are two times you should avoid ISO-8601 timestamps in favor of epoch timestamps. The first is if you're using DynamoDB Time-to-Live (TTL) to automatically expire items from your table. DynamoDB requires your TTL attribute to be an epoch timestamp of type number in order for TTL to work.
Second, you should use epoch timestamps if you actually plan to do math on your timestamps. For example, imagine you have an attribute that tracks the time at which a user's account runs out. If you have a way in your application where a user can purchase more time, you may want to run an update operation to increment that attribute. If a user purchases another hour of playtime, you could increase the time by 3600 seconds. This would allow you to operate on the timestamp directly without reading it back first.
My last tip is billing-related. DynamoDB offers two different billing modes for operations: provisioned and on-demand. With provisioned capacity, you state in advance the number of read capacity units and write capacity units that you want available for your table. If your table exceeds those limits, you can see throttled reads or writes on your table.
With on-demand pricing, you don't need to provision capacity upfront. You only pay for each request you make to DynamoDB. This means no capacity planning and no throttling (unless you scale extremely quickly!).
Now, as my colleague Ryan has pointed out, you do pay a premium for on-demand pricing. On-demand pricing will cost nearly 7 times as much as the equivalent provisioned table if you are getting 100% utilization.
However, it's unlikely you can get 100% utilization. This is true even at peak times but is even more true if you look at utilization over time. Unless you're configuring your auto-scaling pretty well, you're likely getting 30% utilization or less of your DynamoDB tables at low times.
In many cases, on-demand pricing will actually save you money directly over-provisioned pricing. Even when it doesn't, the total cost of ownership is likely to be lower with on-demand pricing as you are no longer worrying about capacity planning, maintaining auto-scaling infrastructure, or responding to throttling alerts at 3 in the morning.
My suggestion is use on-demand pricing until it hurts. If your DynamoDB bill is not a significant portion of your combined AWS bill and engineering payroll, don't waste the time to fine-tune it.
DynamoDB is quickly becoming the database of choice for more and more developers. Its scaling characteristics, flexible billing model, and serverless-friendly semantics make it a popular option for cloud-native applications.

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.





