

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


DynamoDB has quickly become the database of choice for developers building serverless & cloud-native applications. Its scaling characteristics, pricing model, and consistent performance are all attributes that developers love.
One of the most important concepts to learn with DynamoDB is how to use secondary indexes. In this post, we'll walk through some of my best practices for getting the most out of secondary indexes in DynamoDB. This includes:
If you are new to DynamoDB would like DynamoDB indexes explained, make sure you understand the basics first. Check out the official AWS documentation on secondary indexes.
Let's get started!
The first use case for secondary indexes that I want to cover is when you need to sort on attributes that may change.
If you use a composite primary key in DynamoDB, each item you write to the table must have two elements in the primary key: a partition key and a sort key. You can think of these as comparable to SQL's GROUP BY and ORDER BY -- the partition key groups all items with the same partition key together, and the items are ordered by the value in the sort key.
For example, imagine you have a ticket tracking applications. Organizations sign up for your application and create tickets. One of the access patterns is to allow users to view tickets in order by the most recently updated.
You decide to model your table as follows:
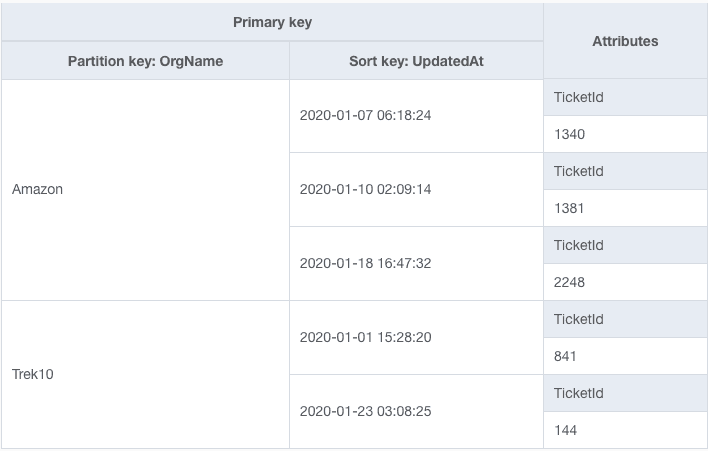
In this table design, the organization name is the partition key, which gives us the 'group by' functionality. Then the timestamp for when the ticket was last updated is the sort key, which gives us 'order by' functionality. With this design, we could use DynamoDB's Query API to fetch the most recent tickets for an organization.
However, this design causes some problems. When updating an item in DynamoDB, you may not change any elements of the primary key. In this case, your primary key includes the UpdatedAt field, which changes whenever you update a ticket. Thus, anytime you update a ticket item, we would need first to delete the existing ticket item, then create a new ticket item with the updated primary key.
We have caused a needlessly complicated operation and one that could result in data loss if you don't handle your operations correctly.
Instead, let's try a different approach. For our primary key, let's use two attributes that won't change. We'll keep the organization name as the partition key but switch to using TicketId as the sort key.
Now our table looks as follows:
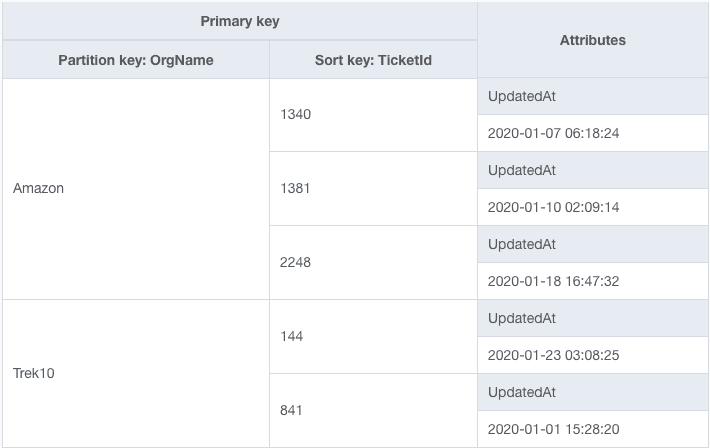
Now we can add a secondary index where the partition key is OrgName and the sort key is UpdatedAt. Each item from the base table is copied into the secondary index, and it looks as follows:
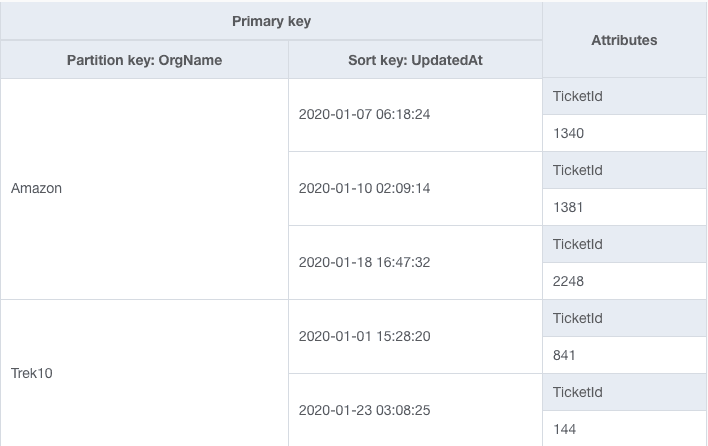
Notice that this is precisely how our original table design used to look. We can use the Query API against our secondary index to satisfy our 'Fetch most recently updated tickets' access pattern. More importantly, we don't need to worry about complicated delete + create logic when updating an item. We can rely on DynamoDB to handle that logic when replicating the data into a secondary index.
A second way to get the most out of your secondary indexes is to overload your secondary indexes. This is a more advanced topic, so let's step back for a moment and explain some background concepts.
When modeling a data model in DynamoDB, it is common to use a single table to store all of your entities, in direct contrast with data modeling in an RDBMS where you have a table for each type of entity.
For more background on single-table design, check out my post on the what, why, and when of single-table design in DynamoDB. For a detailed example of single-table design in action, check out Forrest Brazeal's excellent step-by-step walkthrough of single-table design.
Building a Serverless architecture? Learn more about single-table design, handling complex applications, and new access patterns from a Trek10 DynamoDB expert.
When modeling multiple entity types in a single table, you need to change how you design things. In our ticket tracking example above, we used OrgName and TicketId as the names of the partition key and sort key, respectively, in our primary key. However, if you're storing multiple entity types in a single table, it's unlikely each type has the same types of attributes.
Instead, we'll use more generic names for the elements in our primary key, such as PK for partition key and SK for sort key.
For example, imagine we have an application that includes both Organizations and Users. A User belongs to a particular Organization. We might have our PK and SK values modeled as follows:
Organizations:
ORG#<OrgName>ORG#<OrgName>Users:
ORG#<OrgName>USER#<Username>And an example table would look as follows:
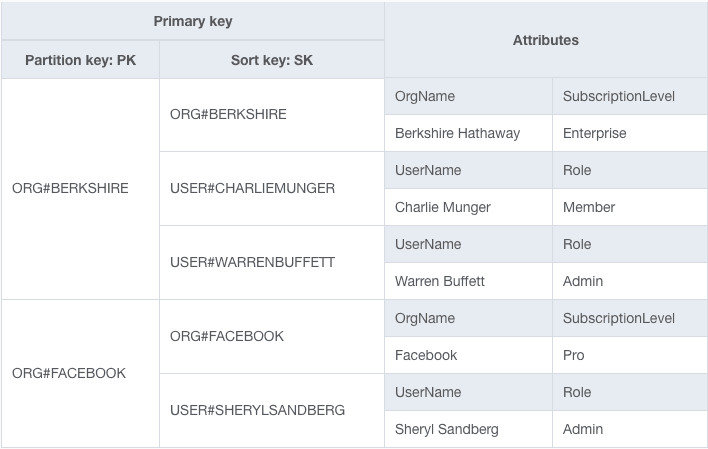
In this table, we have two organizations: Facebook and Berkshire Hathaway. We also have three users: Warren Buffett, Charlie Munger, and Sheryl Sandberg.
Notice how both types of entities are in the same table and use different patterns for the PK and SK to co-exist. By using generic primary key attributes and storing different values there for different types of entities, we're overloading our primary key. The attributes mean different things for different entity types.
You can do the same thing with your secondary indexes. If you have additional access patterns for Organizations and Users, you don't need to create a secondary index tailored to both. You can create a single secondary index that handles additional access patterns for both Organizations and Users.
For example, imagine we have an access pattern where we want to fetch all Organizations in a single request. Additionally, we have an access pattern where we want to fetch Users in a particular Organization in order by the date of creation.
For each item in our table, we could add GSI1PK and GSI1SK values. Again, the names are generic since they will be used for different things.
For the Organization items, the GSI1PK will be ORGANIZATIONS, and the GSI1SK will be the Organization's name.
For the User items, the GSI1PK will be ORG#<OrgName> to group all users in an Organization together. Then the GSI1SK will be the date the user was created to provide sorting.
Our base table now looks as follows:
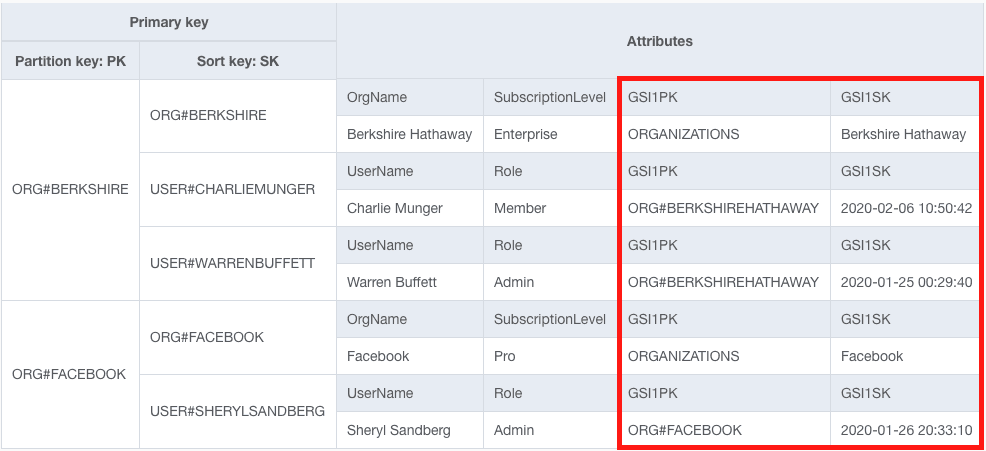
Notice the attributes outlined in red that we've added to each item.
If you switch to the GSI1 view, our index looks as follows:
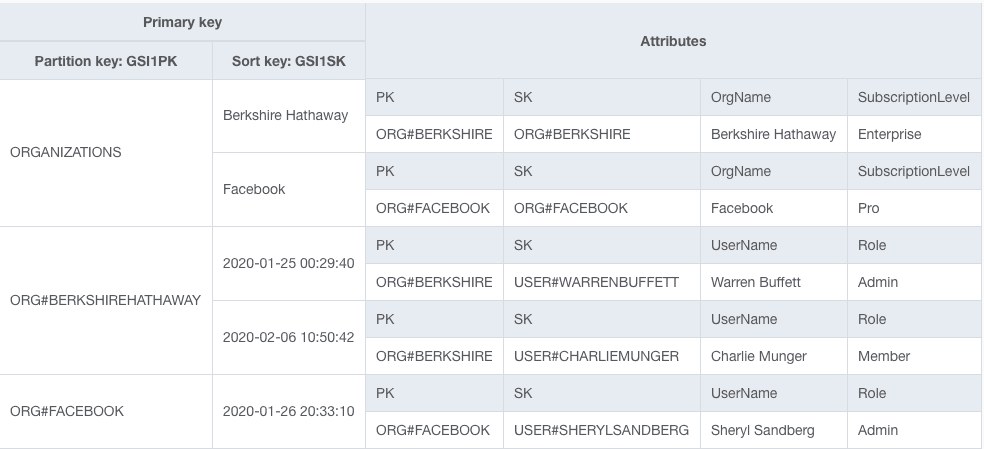
The top item collection includes all Organizations, and the next two include the Users for Berkshire Hathaway and Facebook, respectively. By overloading our secondary index key schema, we have satisfied two access patterns in a single index.
When using global secondary indexes, you need to provision read and write capacity for each index separately from that of your base table. One of the big benefits of overloading your secondary index is that your provisioned capacity is shared across multiple use cases. It reduces your overall operations burden and can save you money.
The final pro-tip for using secondary indexes is to take advantage of sparse indexes. Let's first see what a sparse index is, then we'll see where it's helpful.
When creating a secondary index, you will define a key schema for the index. When you write an item into your base table, DynamoDB will copy that item into your secondary index if it has the elements of the key schema for your secondary index. Crucially, if an item doesn't have those elements, it won't be copied into the secondary index.
This is the important concept behind a sparse index. A sparse index is one that intentionally excludes certain items from your table to help satisfy a query. And this can be an instrumental pattern when modeling with DynamoDB.
Note: if you're using overloaded indexes, as described above, many of your secondary indexes might technically be sparse indexes. Imagine you have a table that has three different entity types -- Organization, User, and Ticket. If two of those entities have two access patterns while the third entity only has one, the two entities will likely be projected into an overloaded secondary index. Technically, this is a sparse index because it doesn't include all items in your base table. However, it's a less-specific version of the sparse index pattern.
I like to call it a sparse index when there is an explicit intention to use the sparseness of the index for data modeling. This shows up most clearly in two situations:
Filtering within an entity type based on a particular condition
Projecting a single type of entity into a secondary index.
Let's look at each of these in turn.
The first example of using a sparse index is when you filter within an entity type based on a particular condition.
In our example in the previous section on overloading indexes, we had two entity types: Organizations and Users. Imagine that you had an access pattern that wanted to fetch all Users that had Administrator privileges within a particular Organization.
If an Organization had a large number of Users and the condition we want is sufficiently rare, it would be very wasteful to read all Users and filter out those that are not administrators. The access pattern would be slow, and we would expend a lot of read capacity on discarded items.
Instead, we could use a sparse index to help. To do this, we would add an attribute to only those User items which have Administrator privileges in their Organization.
Let's slightly modify our example from the last section. Imagine we still have the Organizations access pattern, but we don't need to fetch Users within an Organization ordered by the date they were created. Instead, we want to fetch only Users within an Organization that are Administrators.
We'll keep the same GSI1PK and GSI1SK pattern for Organizations. For Users, we'll still use ORG#<OrgName> as the GSI1PK, but we'll only have a value in GSI1SK if the user is an Administrator.
Our table would look as follows:
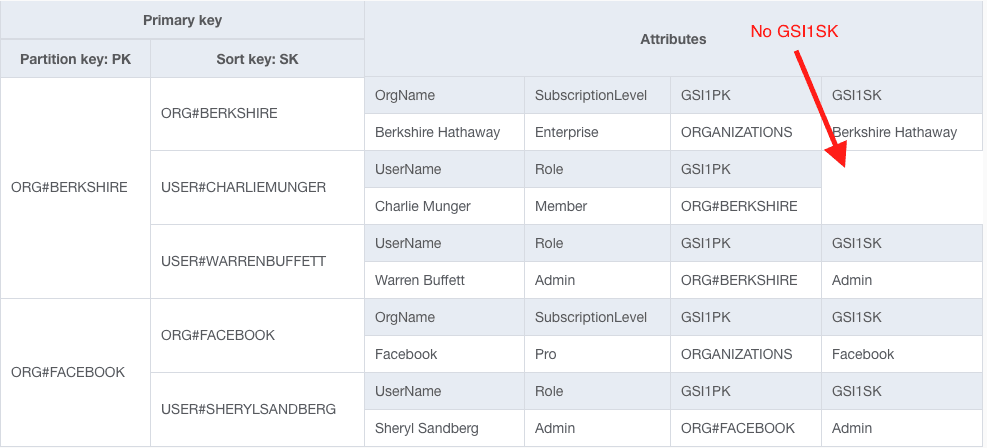
Notice that both Warren Buffett and Sheryl Sandberg have values for GSI1SK but Charlie Munger does not, as he is not an admin.
Let's take a look at our secondary index:
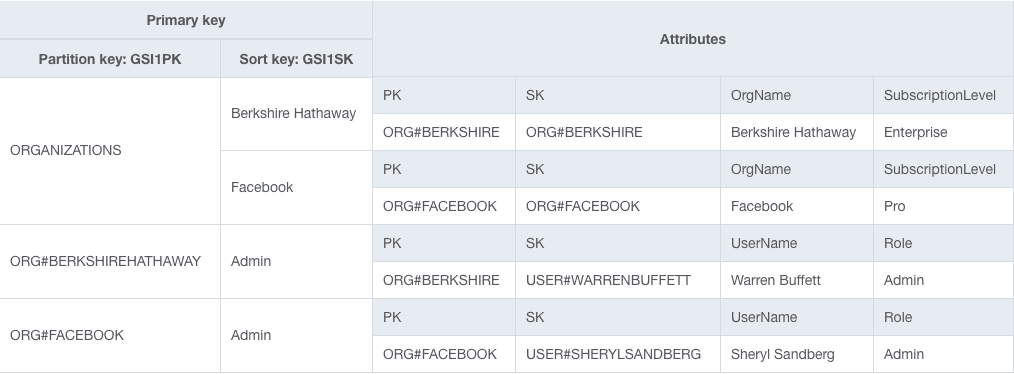
We are still using an overloaded secondary index and handling multiple access patterns in a single index. However, we're intentionally using a sparse index strategy to filter out User items that are not Administrators.
The next strategy is a bit different. Rather than using an overloaded index, it uses a dedicated sparse index to handle a single type of entity.
A second example of where I like to use a sparse index is if I want to project a single type of entity into an index. Let's see an example of where this can be useful.
Imagine I have an e-commerce application. I have several different entity types in my application, including Customers that make purchases, Orders that indicate a particular purchase, and InventoryItems that represent products I have available for sale.
My table might look as follows:
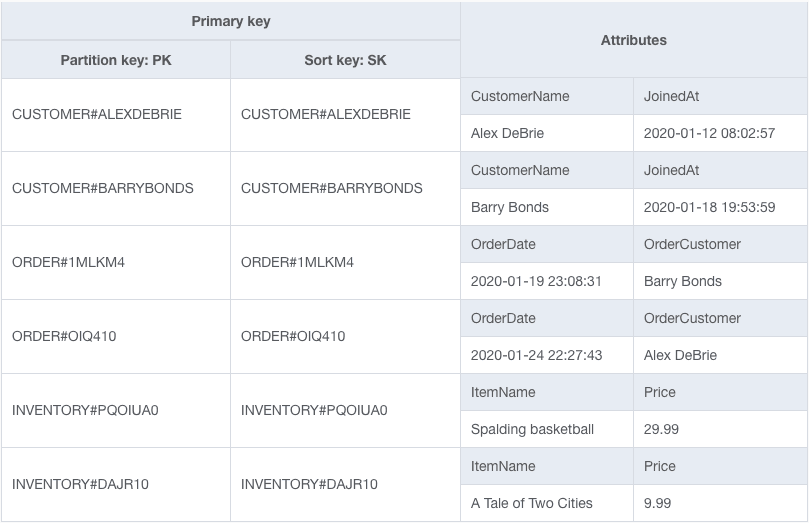
Notice that the table includes Customers, Orders, and InventoryItems, as discussed, and these items are interspersed across the table.
My marketing department occasionally wants to send marketing emails to all Customers to alert them of hot sales or new products. To find all my Customers in my base table is an expensive task, as I would need to scan my entire table and filter out the items that aren't Customers. This is a big waste of time and of my table's read capacity.
Instead of doing that, I'll add an attribute called CustomerIndexId on my Customer items. Now my table looks as follows:
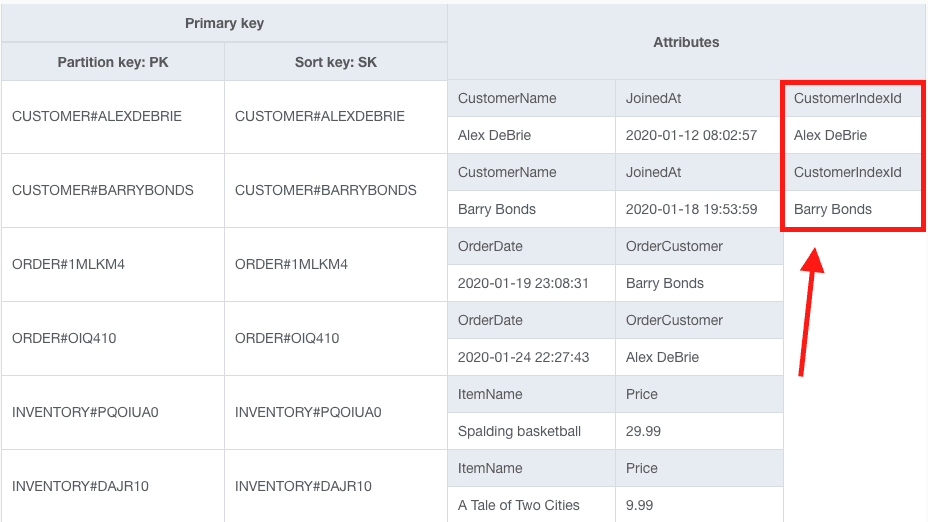
Notice the Customer items now have an attribute named CustomerIndexId as outlined in red.
Then, I create a secondary index called CustomerIndex that uses CustomerIndexId as the partition key. Only Customer items have that attribute, so they are the only ones projected into that index.
The secondary index looks as follows:
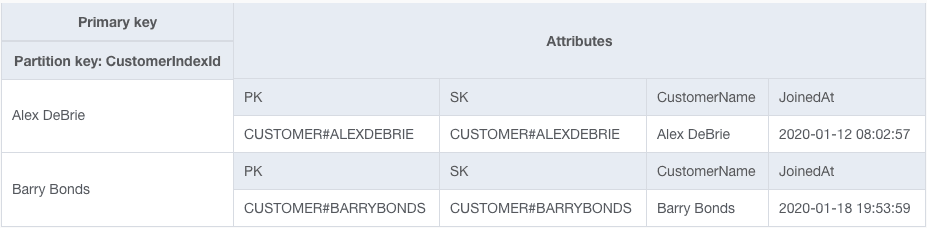
Only the Customer items are projected into this table. Now when the marketing department wants to find all Customers to send marketing emails, they can run a Scan operation on the CustomerIndex, which is much more targeted and efficient. By isolating all items of a particular type in the index, our sparse index makes finding all items of that type much faster.
Again, notice that this strategy does not work with index overloading. With index overloading, we're using a secondary index to index different entity types in different ways. However, this strategy relies on projecting only a single entity type into the secondary index.
We learned some great strategies to get the most out of DynamoDB secondary indexes in this post.
We saw how secondary indexes are a great way to sort your data on changing attributes. This is a great pattern for leaderboards or for finding most recently updated as you can rely on DynamoDB to handle the deletion and re-creation necessary to re-sort your items.
We learned about overloading your secondary indexes to reduce the total number of indexes on your table. And finally, we saw how sparse indexes can enable specialized access patterns by providing targeted filters on your table.
While I regularly use secondary indexes in my DynamoDB data models, the fun and function doesn't stop there. For more advanced topics and in-depth guidance, check out my DynamoDB Book or request a Trek10 DynamoDB Workshop

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.






