

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


Seriously, watch that video, then come back to this article. You won't be disappointed.
Of all the sessions I’ve seen from AWS re:Invent 2018, my favorite is certainly this bewildering drop-kick of NoSQL expertise from AWS Principal Technologist and certified outer space wizard Rick Houlihan.
So, for the first 45 minutes of this #reInvent session I was nodding my head like "Yup, that's how I think about DynamoDB." Then Rick morphed into some kind of NoSQL wizard from outer space and my mind exploded. Absolute must watch: https://t.co/YNr6TcMEJI
— Forrest Brazeal (@forrestbrazeal) December 4, 2018
Rick cracks the lid on a can of worms that many of us who design DynamoDB tables try to avoid: the fact that DynamoDB is not just a key-value store for simple item lookups. If you design it properly, a single DynamoDB table can handle the access patterns of a legitimate multi-table relational database without breaking a sweat.
That little phrase “designed properly” is the caveat, of course. Rick’s video, and the related documentation that I suspect he had a hand in, are densely packed with advice on how to construct a DynamoDB table that will match your relational DB’s query performance at arbitrary horizontal scale.
Not gonna lie though, it’s heavy stuff, especially for us non-certified outer space wizards.
So in this post, I want to work through some DynamoDB single-table design considerations in step-by-step detail. We won’t cover every possible design pattern, but hopefully you’ll start to get a feel for the possible use cases and the inevitable tradeoffs. We’ll conclude with the ultimate question: is any of this a good idea when relational databases are still, like, right over there?
Fair warning: I dive in deep! If you just want to skip to the high-level conclusion, take the shortcut!
So what relational database should we, er, Dynamize? I decided to go with the most SQL-y example I could think of: Northwind, the classic relational database used to teach the Microsoft Access product back in the ’90s.
Here’s the full Northwind ERD. It’s not huge, but it’s at least as complex as the data requirements of many modern microservices you might want to back with DynamoDB.
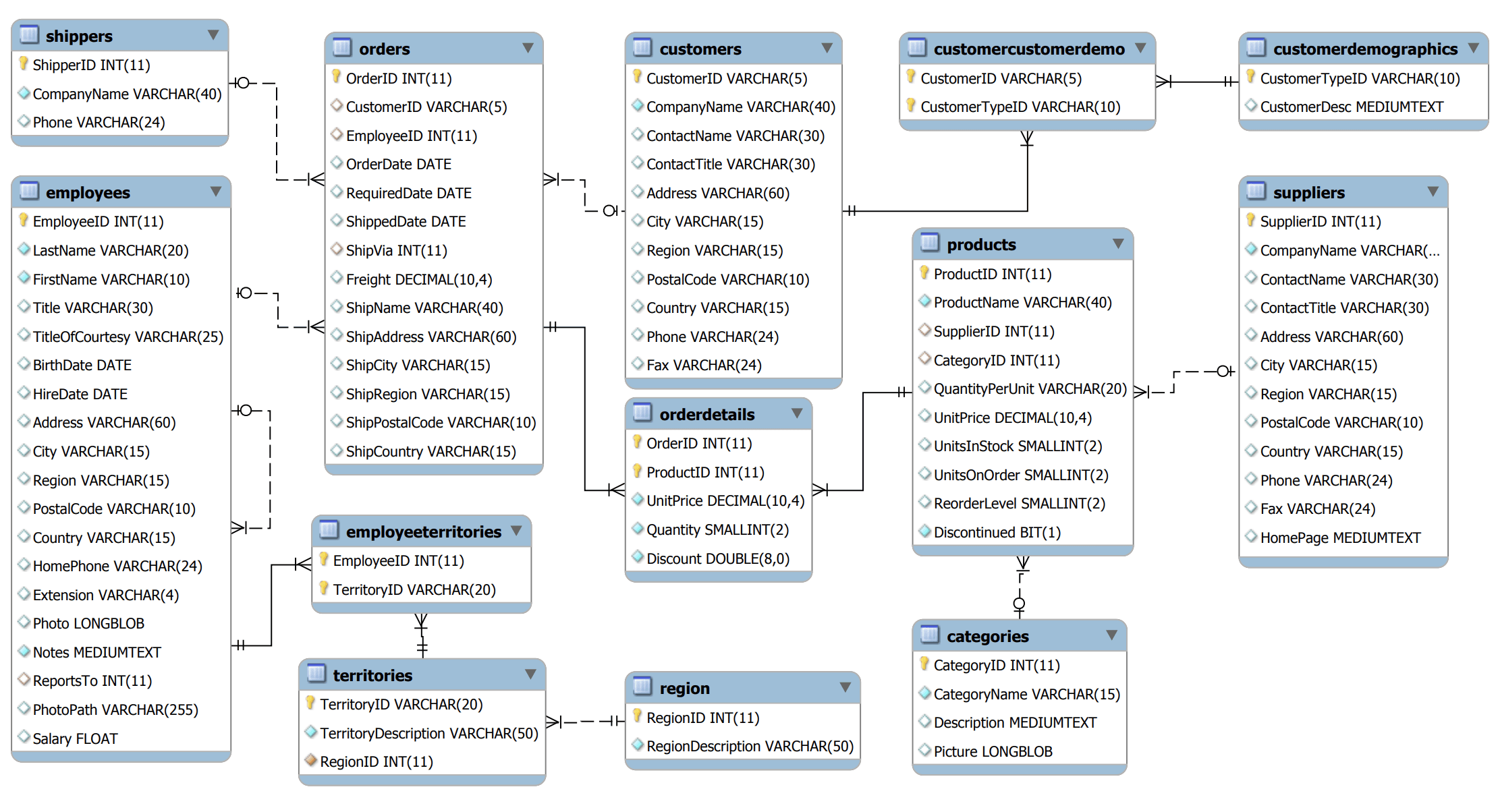
Lo and behold, the sample data for the Northwind schema is available in cleaned-up CSV form on Github. We’ll ignore a couple of the ancillary tables to focus on the “big eight”: Categories, Customers, Employees, Orders/Order Details, Products, Shippers, and Suppliers.
I’ve included all the code necessary to create the DynamoDB table and load the data as shown throughout this post in this Github repo. Feel free to check it out and play along!
Now, how do we turn our ERD and CSV tables into a DynamoDB table?
Right away, we come up against a huge difference between DynamoDB and a relational database: our data model is going to be wholly pragmatic, rather than theoretically self-consistent. We’re going to mold our table specifically around the things we need to do with the data, kind of like spraying insulation foam into a roof.
In the real world, we’d gather these requirements from the app team, prospective users, etc. This isn’t a real use case, though, so we’ll have to invent some access patterns by looking at the ERD. Here are some arbitrary query requirements I came up with:
All these would be simple SQL queries involving at most a couple of joins. (We’ll save write patterns for a future post.) But remember, we don’t have JOIN or GROUP BY in DynamoDB. Instead, we’ve got to structure our data in such a way that it’s “pre-joined” right in the table.
This brings us to one of the most important precepts in DynamoDB single-table design:
Attribute names have no relationship to attribute values.
Not only is our “key-value store” schema-less; in a way, it’s also keyless. We need to get used to thinking of the attribute names on a DynamoDB item as arbitrary. Our “partition key” attribute on the table may contain a different type of value depending on whether it’s an Order, a Product, an Employee, or whatever:
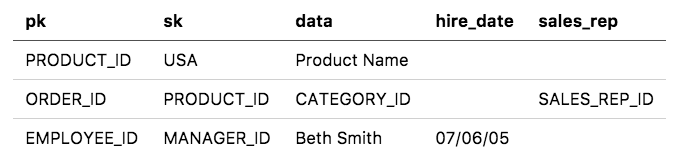
Storing different types of data in the same attribute feels weird and squicky, I know. But it’s actually super powerful. This technique is called index overloading, and it will enable us to squash tons of access patterns into a very small number of indexes.
The three generic attributes will be used to support two indexes: the main table index which uses pk as the partition and sk as the sort key, and a global secondary index which uses sk as the partition and data as the sort.
What's the big deal about indexes, anyway? In general, your DynamoDB cost and performance will be best if you restrict yourself to "gets" (key/value lookups on single items) and "queries" (conditional lookup on items that have the same partition key, but different range/sort keys). Scanning, where you indiscriminately gobble all items from a table, is a slow, expensive antipattern. Useful gets and queries require ... useful indexes. So here we are.
These two indexes, as we’ll see, will open up a huge number of access patterns. The other attributes in the table can be named whatever you want; they don’t have to be consistent between items. But even if you give every attribute of every item a random name, it doesn’t affect the behavior of the table at all. (It just makes the table layout harder for humans to read and understand … as we’ll discuss further below.)
Each Customer, each Order, each Shipper record gets an item in our new table. In each of our cases, we’ll make the pk attribute correspond to the primary key of the relational record. The sk and data attributes, though, we’ll vary based on the kinds of queries we need to write. See the breakdown below:

We’ve left out the “OrderDetails” join table for now; it’ll get special treatment in the next step.
Let’s note a couple of tricks here:
Order, Product, and Supplier records use a static value as the partition key for GS1. This lets us look up all items of a particular type (such as all orders that match a date range) without resorting to an expensive scan operation. You can think of this as a workaround for the loss of our precious attribute keys: we’re using a value as a key instead.data field for the Customer and Supplier records. By combining all the address details into one field, we can get country, region and city lookups for the price of a single GSI.We're basically playing Tetris with our data at this point, sliding different values in and out of our limited GSI slots to get the maximum utility. And we're not done, because we still have to...
Why are we so obsessed with minimizing global secondary indexes? Wouldn't it be easier just to slap a ton of indexes on this table? For a long time, the answer was no; DynamoDB tables had a hard limit of 5 GSIs. DynamoDB just recently raised that limit to a soft 20, meaning you probably can have an undefined number of GSIs on a table.
But lots of GSIs make writes geometrically more expensive, consuming extra capacity units each time you update an item. So we'll win on cost and performance if we can squash our lookups down into the smallest possible index footprint.
DynamoDB best practices borrow from graph theory the concept of adjacency lists, which are … a bit of a slippery concept. To hang onto the graph idea for a moment, you can think of all the items we’ve placed in our table so far as “node” records. They correspond to entities, like customers and orders. We’re now going to create some additional “edge” records that represent the many-to-many relationships between nodes.
In the Northwind dataset, the many-to-many relationship we’ll focus on is expressed in the OrderDetails join table. An order can have many products, one product can appear in many orders, and the attributes of that relationship are expressed in OrderDetails. We’ll model this relationship by placing the OrderDetails records in the Order partition of our table.
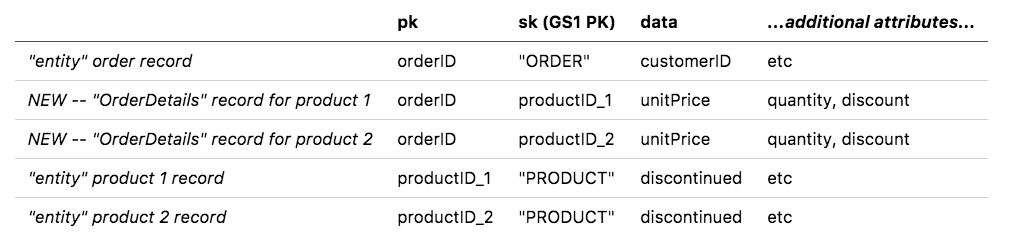
Why are we putting all this stuff in one table again? The DynamoDB documentation emphatically recommends using as few tables as possible, usually one per app/service unless you have hugely divergent access patterns. Locating your related data close together will give you Dynamo's performance and scale benefits without the latency and frustration of querying multiple tables via HTTP and trying to "join" them client-side.
That said, I see lots of relational databases that should be split into separate DynamoDB tables, because the same database is used as a dumping ground for all kinds of unrelated data. That 70-GB table of access logs in your Postgres database doesn't need to go in the same DynamoDB table with your product and order data.
What does this get us? We now have the ability to query the primary table partition to get all products in an order. We can query the GS1 PK to do a reverse lookup on all the orders of a given product. This is the adjacency list pattern. You can try it yourself with the "EmployeeTerritories" join table in the Northwind data, which we haven't included here. You may need to break this access pattern out into its own GSI if you take it much further.
Believe it or not, even with all the tricks we used back in step 2, a single GSI may not be enough to support every possible query! (Shocking, I know.) The good news is that you can add additional GSIs, if needed, without totally disrupting your carefully pieced-together Tetris board. The DynamoDB docs have a good example of adding a second GSI with specially-constructed partition and sort keys to handle certain types of range queries.
In our case, though, the main table partition plus one GSI are more than enough to handle all the use cases we defined in step 1. Let’s break down the queries:
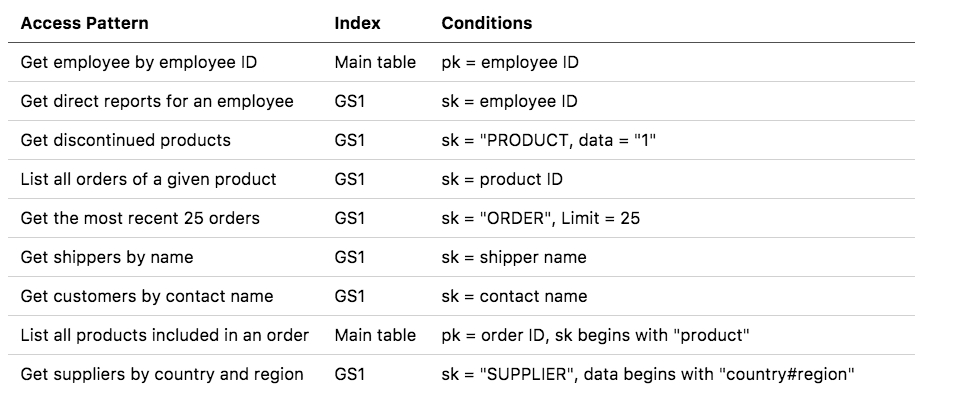
What about sharding? We've been thinking a lot about how to make our single-table queries easy, but not necessarily about how to make them fast. Even with DynamoDB's new adaptive capacity functionality, you want to keep your access patterns smoothed out so you don't have disproportionate load on a single partition. This often involves creating an index with randomized keys. Alex DeBrie has a marvelous breakdown in his DynamoDB guide of how this works, and when you might need it. (In particular, sharding would be important for our GSIs with a static partition key, like "ORDER" -- right now that's a lot of records packed into a single partition.)
You can see working examples of all these queries using the AWS Python SDK in the accompanying repo. Plus, we've preserved individual key-value lookup of every entity in the table, so we haven't strayed too far from DynamoDB's roots.
We now have a basic blueprint to convert a relational database into a single DynamoDB table. But remember, this is a spray-foam approach to data. Like insulation hardened in the contours of a ceiling, our DynamoDB single-table data model is both informal and inflexible. It’s not necessarily going to accommodate new access patterns.
For example, suppose we need to see all products in a given category. The “Product” records have a CategoryID, but it’s not included in any of our indexes at the moment. Our options are:
As you can see, tradeoffs abound! Only you can decide which option makes the most sense for the long-term health of your app and the sanity of your developers. The more GSIs with generic attributes you add, the harder this table will be to read and understand without a load of supporting documentation.
In fact, a well-optimized single-table DynamoDB layout looks more like machine code than a simple spreadsheet — despite all the bespoke, human finagling it took to create it.
Which leads to the most important question of all:
About a year ago, I wrote a fairly popular article called “Why DynamoDB isn’t for everyone”. Many of the technical criticisms of DynamoDB I put forth at that time (lack of operational controls such as backup/restore; a persistent problem with hot keys) have since been partially or fully resolved due to a truly awe-inspiring run of feature releases from the DynamoDB team.
However, the central argument of that article remains valid: DynamoDB is a powerful tool when used properly, but if you don’t know what you’re doing it’s a deceptively user-friendly guide into madness. And the further you stray into esoteric applications like relational modeling, the more sure you’d better be that you know what you’re getting into. Especially with SQL-friendly “serverless” databases like Amazon Aurora hitting their stride, you have a lot of fully-managed options with a smaller learning curve.
That said, remember that Amazon’s original Dynamo paper was predicated on the observation that most interactions with their vast Oracle databases were simple key-value reads, no JOINs or other relational magic required.
In the same way, a lot of superficially relational datasets boil down into a relatively small number of usage patterns. If you can work through the steps in this post to identify and implement those patterns for your data, DynamoDB’s scale, performance and low operational overhead may seem more compelling than ever.
Unless, you know, you’re still a big fan of Microsoft Access.
Thanks to Alex DeBrie, Jared Short, and Andy Warzon for providing technical review on this post.
Need DynamoDB expertise? Trek10 has been there, done that. If we can help you, feel free to let us know.

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.





