

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


The most recent re:invent announced numerous improvements to both Lambda and Fargate. While these improvements may have unlocked additional capabilities, they also did a lot to converge the two services, removing a lot of technical and financial barriers that may have previously been a deciding factor on which technology to use for a new project. In this post I will go through a few different categories and compare AWS Fargate vs Lambda, demonstrating the remaining strengths and weaknesses of each approach given the newly added features.
Let’s start with a fun one - how do Lambda and Fargate compare cost-wise? For Lambda vs Fargate pricing comparison, it’s complicated - it highly depends on your use case. Since there have already been many posts on this subject, I’ll focus instead on how the most recent re:Invent announcements affect things.
For starters, AWS announced HTTP APIs for API Gateway. This feature promises higher performance and at a lower price point. If you can live without some of the features of REST APIs, you can pay a lower rate - $1.00 per million requests instead of $3.50 per million requests. Accounting for lambda execution costs, building a simple api endpoint that processes in 100ms and uses 128 MB memory, you’re looking at about $1.408 per million requests.
Another Lambda feature, Provisioned Concurrency, complicates this a bit. There are some mixed reactions to this feature due to it making lambda billed by time, not just usage. For a fully utilized lambda, this could lead to a 16% cost savings at the expense of predicting usage.
The Fargate equivalent, spinning up a 256 CPU unit (1/4 vCPU) 512 MB container behind an Application Load Balancer (ALB) is priced differently - by (partial) hours, not by request. This setup would cost about $0.035 per hour. If you are able to use Fargate Spot, another new feature announced at re:Invent, this price drops even further - $0.0262 per hour. Here is a quick chart to estimate the cost per 1 million messages at various rates:
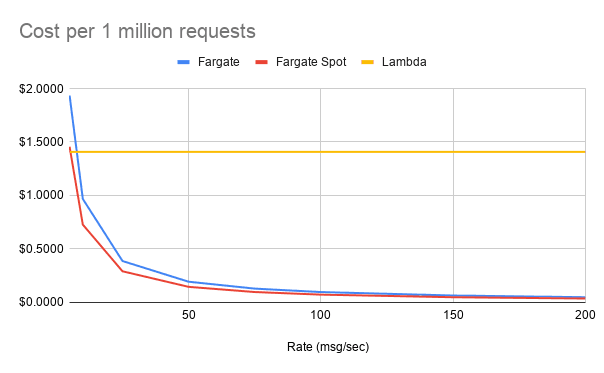
Despite the price reduction of HTTP APIs, unless your traffic is extremely spiky, Fargate is a clear winner when it comes to APIs. It is important to call out that API Gateway does more than an ALB though, providing rate limiting (though not on HTTP APIs yet) and authorization. Depending on your needs, these would need to be implemented in Fargate, but are common features of the most popular web frameworks for most languages.
I also want to do a quick comparison when processing messages from a queue, as this will be more fair. The majority of the expense for lambda in the prior example came from the API Gateway, and the invocation cost of the lambda itself. Since Lambda can process messages in batch from queues (max of 10 per batch from SQS, 10,000 msgs or 6 MB for Kinesis), the invocation costs are much lower. Assuming a per-message processing time of 50 ms, and batch sizes of 10 for SQS and 100 for Kinesis, the pricing would be $0.124 per million for SQS and $0.106 per million for Kinesis.
For Fargate, here is another chart showing the cost to process 1 million messages at various rates:
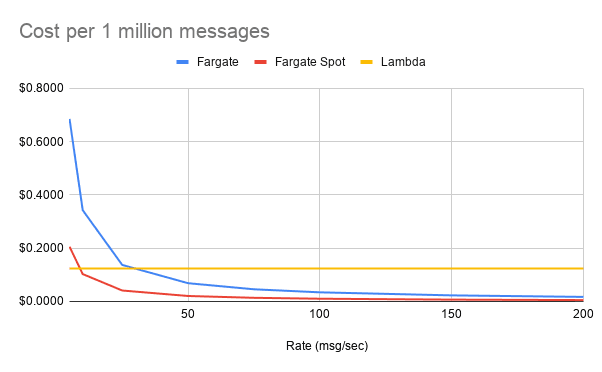
This scenario makes Lambda much more competitive, even when using spot pricing, which is usually a viable option for async processing tasks. For spiky loads, and low to moderate traffic, Lambda still comes out well here.
One final new feature with cost implications is the RDS Proxy. Developers using Lambda have traditionally had to rely upon workarounds, like storing database connections in a global scope, to prevent some connection issues, but this has been a far from ideal solution as there is no way to clean up connections when the Lambda is killed, and unless you set reserved concurrency on the Lambda, you can still exhaust available connections to a database. RDS Proxy fixes this by adding a new service, which is pay-per-hour, between your Lambda and the database, and it manages the connection pool for you. While this is a great feature, adding a fixed cost based on time and number of vCPUs on the database, can quickly make this price prohibitive when compared to Fargate, which can handle connection pools itself.
When it comes to creating new applications, SAM makes the process incredibly easy for Lambda based architectures. By providing defaults for required infrastructure components, such as the API Gateway and roles, you can focus purely on the code first, and gradually replace default resources as your application needs it. It also provides easy mechanisms to trigger Lambdas based on a variety of events. Despite some circular dependency issues, the entire process is relatively easy to work with.
Fargate, on the other hand, requires far more work to get going with. The existing ECS CLI tool helps streamline a bit of the Elastic Container Service (ECS) portion a bit, but the rest of the architecture (storage, caching, etc) need managed separately. A newly announced tool, version 2 of the ECS CLI show some promise in this area, but is pretty early in development.
As of early 2020, Lambda remains far easier to use for spinning up new architectures. When it comes to new deploys and ongoing maintenance, things even out a lot more though. New deployments for both consist of updating CloudFormation templates and deploying. For both Lambda and Fargate, AWS manages the underlying servers, meaning developers don’t have to worry about security patches and just focus on the application code itself. Developers will need to update dependencies and fix bugs on both platforms, but for Fargate, developers also need to maintain the base image. This can be a positive or negative - it is an additional step, but does allow for more control. The easy path would be to base your Fargate containers off of Amazon Linux 2, which are managed by AWS and is the basis for the Lambda runtimes anyway. For the more advanced, you can use stripped down containers like distroless or build images containing just a compiled binary with no OS, further reducing the attack surface. AWS also recently announced image scanning for ECR in order to automatically scan for known vulnerabilities.
Lambda particularly shines in two areas - scale to zero, and rapid scaling. The fact that you don’t have to pay for idle applications is very useful for low traffic workloads and dev environments. The ability to scale from 0-1000 rapidly is important for spiky, unpredictable traffic.
Since AWS manages underlying servers, Fargate can scale much more quickly than traditional ECS which runs on top of managed EC2 instances. Container scaling events on ECS may have to wait for the underlying cluster to resize, while Fargate can immediately add tasks. However, since capacity is added in a stair-step fashion, it is a bit less capable than Lambda. Adding new container increases the processing capacity by hundreds of messages per second which means you are usually paying for more compute than necessary. Another downside of Fargate is inability to natively scale to 0, although it is easy to shut down Fargate tasks on a scheduled or manual basis in order to save money in development environments that don’t need to run outside of business hours.
Since Fargate runs on more dedicated resources, it is no surprise that performance will be better than on Lambda. The question is, then, how much better and does it even matter? To test this, I created HTTP endpoints in both Fargate and Lambda to do some light data manipulation and save/retrieve results to/from DynamoDB. Both services were deployed in us-east-1, and I hit the endpoints from my workstation in central Indiana. When sending 10 KB payloads at 50 messages/second, I recorded the following latencies (in milliseconds) at various percentiles:

Though Fargate did end up being faster, I think the more important quality here is the consistency of the response times. But the meaning of these numbers is entirely dependent on the use case. There are a lot of use cases where the increased latency and inconsistency are not a problem, especially when the APIs are doing enough work that the additional 100ms overhead isn’t as noticeable. For more time sensitive or critical APIs, such as ones that are offered as a paid service, it is more important to offer a fast and consistent experience.
For asynchronous, queue-consuming tasks, performance is less of an issue. Outside of edge cases, either platform will do the job admirably.
Re:Invent 2019 announced a lot of features that helped blur the line between Lambda and Fargate. Lambda has added features to help deal with cold starts and working with relational databases, and Fargate has introduced a lower pricing option in Fargate Spot. Though it was announced prior to re:Invent, Savings Plans are another way customers can save money on predictable Fargate workloads.
Despite the recent improvements, there are still areas where Lambda and Fargate do not compete due to technical limitations. Things like long-running tasks or background processing aren’t as doable in Lambda. Some event sources, such as DynamoDB streams, cannot be directly processed by Fargate. Looking forward to 2020 and beyond, I believe the number of these technical limitations will continue to decrease as Lambda and Fargate continue to converge on feature sets. The new ECS CLI is already showing a lot of promise in bringing SAM style ease-of-deployments to Fargate. Also, Lambda has a history of increasing limits and supporting new runtimes. It will be interesting to see where these services continue to evolve.
So which tool is the best for your organization? Lambda vs Fargate? It depends! There is no silver bullet, and I cannot hope to go through every possible scenario. What I can say is that for many applications, you can build cost-efficient, performant, reliable architectures with either platform. With the recent new features and cost savings options, the right architecture may no longer depend on cost or technical concerns and instead depend on personnel. Depending on what the expertise and experience is on your team, the cost of retraining people may far outweigh any savings to be had by using a different platform. Or, it may be worth using a less efficient solution in one place in order to use the same tools as the rest of the organization.
In any case, the future of serverless compute on AWS is bright, and we here at Trek10 have a staff of knowledgeable architects and engineers ready to assist you in building efficient and effective cloud-native solutions on AWS!

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.







