


Serverless
Replacing Amazon S3 Events with Amazon S3 Data Events
How to synthesize an (almost) identical payload using Amazon EventBridge rules.

In June 2017, Trek10 got spacklepunched by AWS when they launched when DynamoDB launched Auto Scaling natively. See here. This wasn't the first and won't be the last time, which is why we love working in such a fast-paced ecosystem.
The original post is below, but we highly recommend you ignore it and use native autoscaling!
Mon, 02 May 2016
WE HAVE OPEN SOURCED AN IMPLEMENTATION: CHECK IT OUT
So you’re building your serverless app on AWS for unlimited scalability and true pay-per-use. Your web server is Amazon API Gateway - unlimited scale with zero scaling effort. Your app server is AWS Lambda - ditto, unlimited scale with zero scaling effort. And your database is Amazon DynamoDB - unlimited scale… but not quite zero scaling effort.
With DynamoDB you have to set provisioned read and write capacity for every table and global secondary index. Set something too low, and your app will crash just like any old server-based app. Set something too high and leave it on 24/7, and your bill might be pretty hefty. So how do we make DynamoDB maintenance-free, perfectly scalable, and with costs that track usage, just like the other components of our system?
The principle is pretty simple… since provisioned read & write throughput can be set via the AWS API, a little bit of code should be able to automate the decision about scaling your capacity up and down in response to your consumed read & write throughput. This idea has actually been around for a while. But that older solution used a server — eww! We obviously need a serverless solution here to keep our overall maintenance footprint low and availability high.
There are two other small issues to tackle:
So with that in mind, here is the basic layout of a serverless DynamoDB Auto Scaling solution:
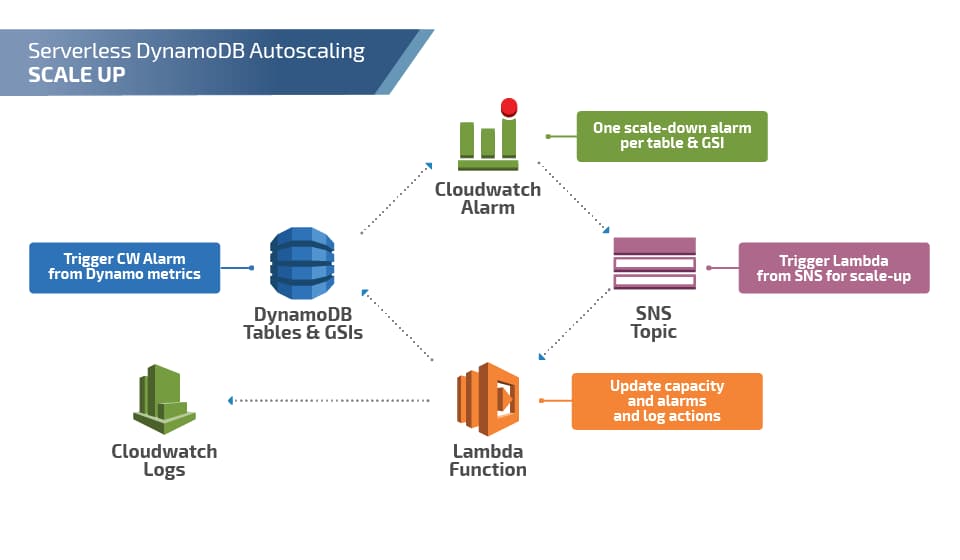
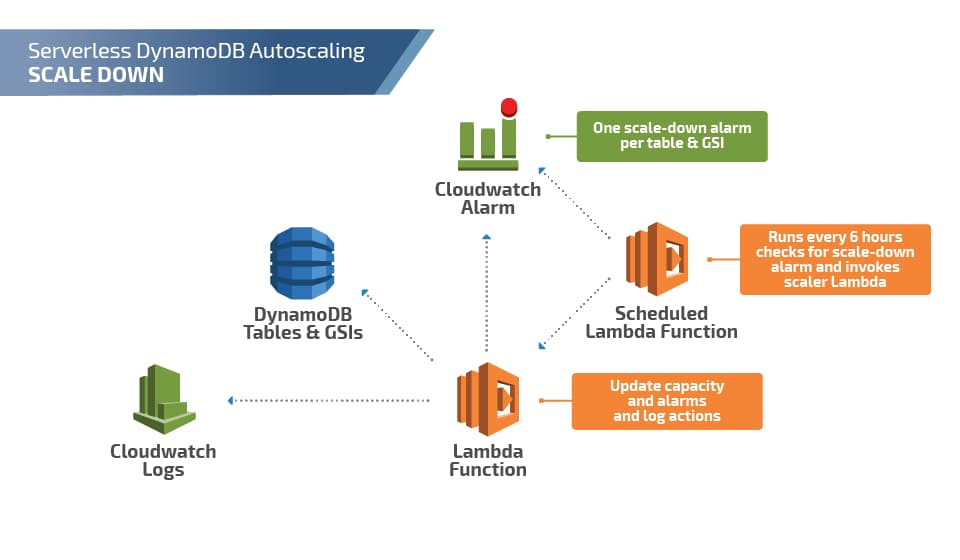
As you can see, scale-up activity is triggered by a CloudWatch Alarm -> SNS Topic -> Lambda function, which updates DynamoDB’s provisioned throughput. Scale-downs are checked every 6 hours (because of the four-times-per-day limit), but the update process is otherwise the same.
One missing piece in these diagrams is the system for managing this: The config tables mentioned earlier and a “configurator” Lambda function that would check the settings in the config table and update CloudWatch alarms appropriately.
So there’s a lot here, but once all built this can be encapsulated into a single CloudFormation template and a single config table. At the end of the day, from the operator’s perspective, it’s fairly simple and incredibly powerful to have a truly unlimited scale with almost no day-to-day effort.
Do you have any ideas about how to Auto Scale DynamoDB? We’d love to hear about them on Twitter, LinkedIn, or email us directly.

How to synthesize an (almost) identical payload using Amazon EventBridge rules.



