

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


One of the experiences I’ve had when working with Amazon DynamoDB and NoSQL databases is that they perform perfectly while testing them, but once out in production, errors shoot through the roof. This problem can cause your system’s performance to tank, higher costs, and errors that are hard to reproduce or even understand. When the team finds the root cause, it's not uncommon for it to be your Amazon DynamoDB or NoSQL database.
A big problem that can happen in systems is when there’s a single record to which everything writes. In systems that don’t have many transactions, this pattern only shows up rarely and randomly. In systems under a significant amount of load, this problem can cripple them. I have seen a variety of these and helped lead teams through these struggles.
In this article, we’ll explore the key three questions to diagnose the type of contention you’re dealing with. After that, we’ll then dive into approaches and common patterns to fix these issues.
When approaching these problems, it's important to first clarify what data is being updated in the creation of resource contention on the system. Getting this clarity will help you understand what the right solution is for your problem.
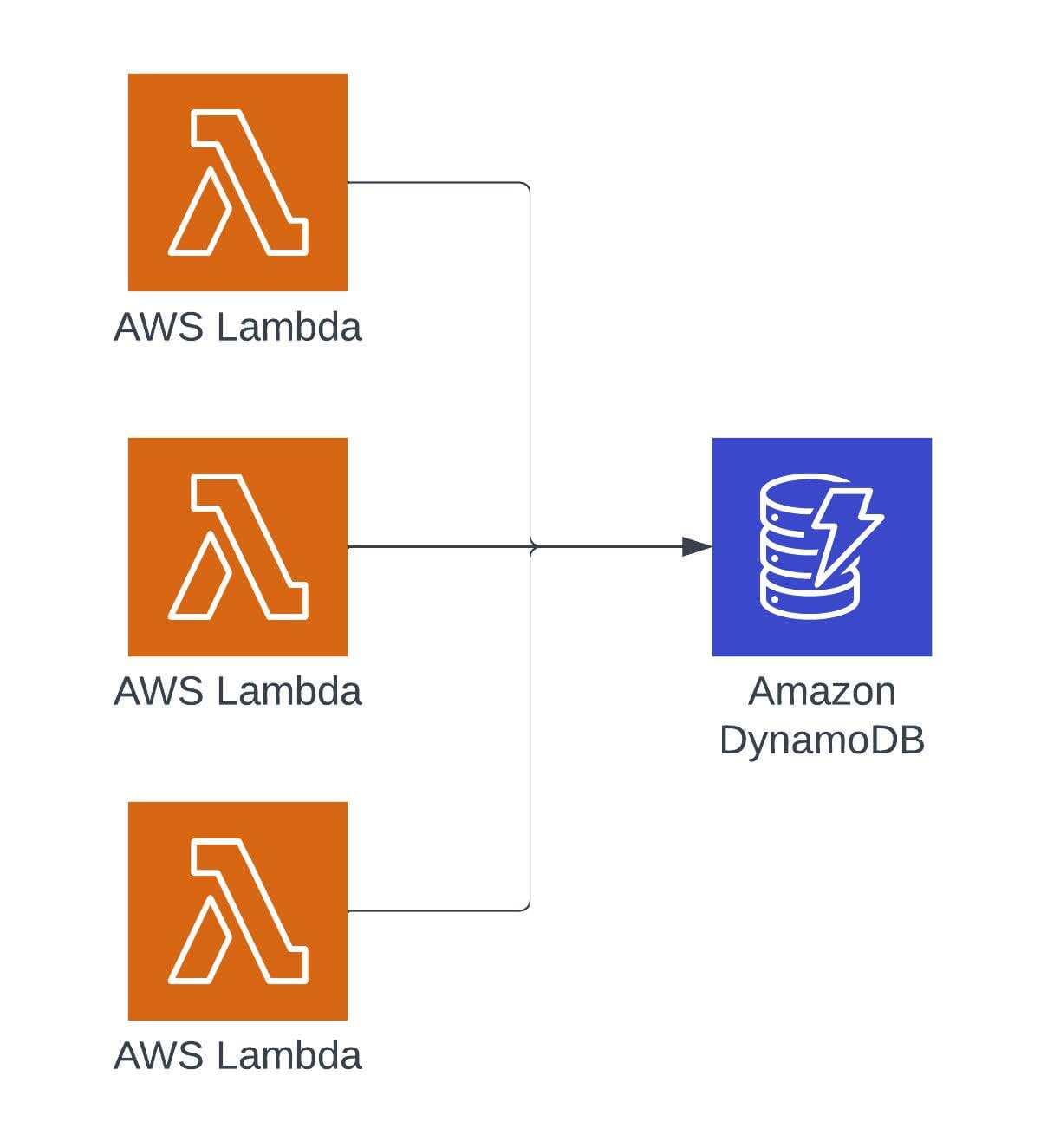
First question: Is the data related to a measurement in a point of time or is it just a simple update of a field? This question helps define the data, how it contributes to the system and what causes it to be a bottleneck.
Second question: Is there more value to be gained if the data was stored as a time series rather than as a single point in time? This question helps identify if there’s potentially a misalignment between what the data is and the approach being used to store the data.
Third question: How are you ensuring data integrity? With many systems potentially contributing to the same record, it's fairly common to try and ensure that updates don’t overwrite each other. This happens most often with a NoSQL design pattern of “Get -> Modify -> Put”. In this pattern, the entire object is being overwritten. If other updates happen to the object after the “Get” operation, then they could be lost in the “Put” operation. To fix this, teams will put a method in place to identify if the original state of the object is still present for the “Put” operation.
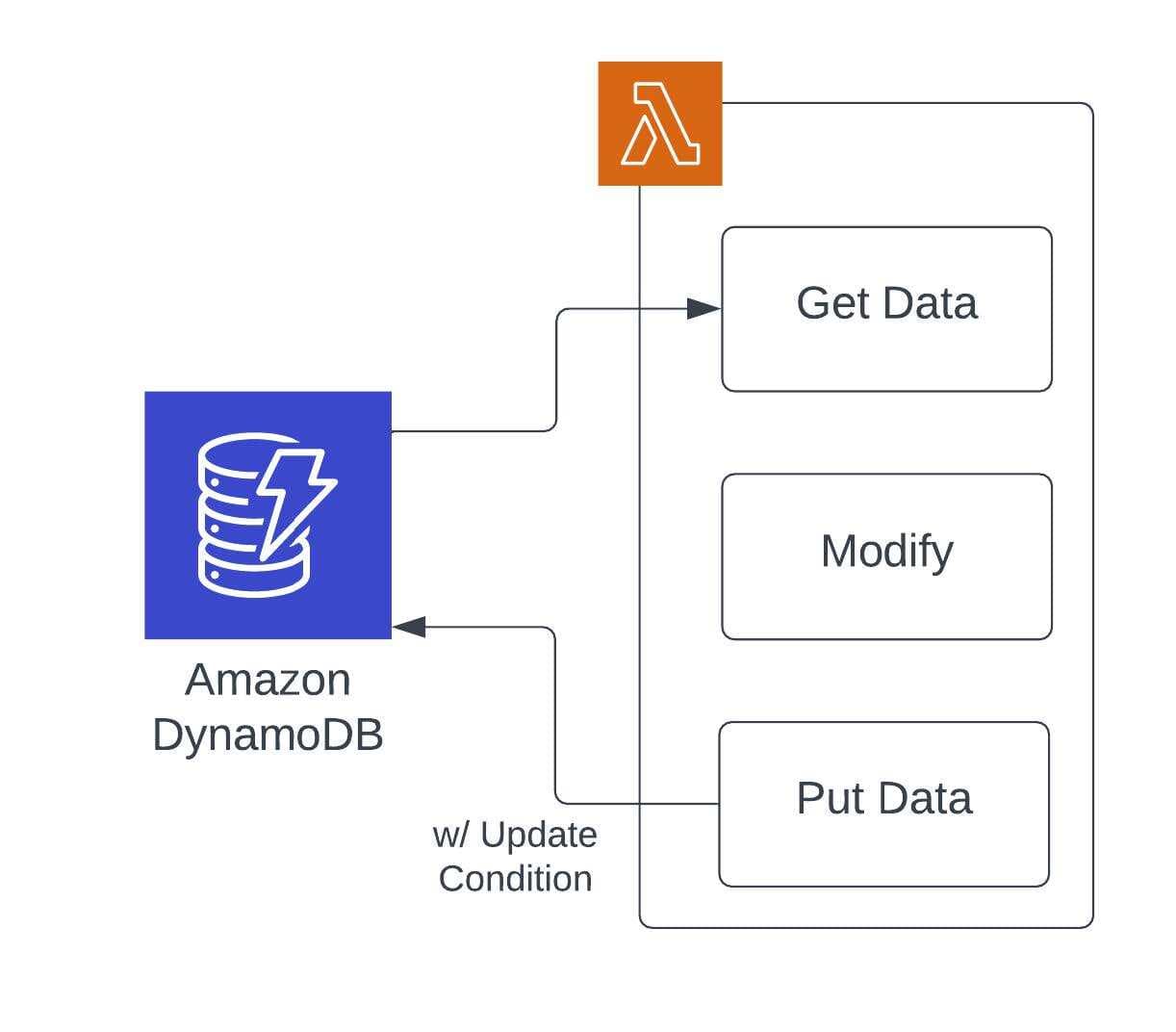
If the data is based on an event or measurement at a point in time (1: Point In Time, 2: Yes, 3: Object Locking), then your best option is to store the information as point-in-time measurements outside of your data model. In this case, moving the data over to Amazon Timestream will increase the value to your product, due to time-based analysis potential, and eliminate data contention. Amazon Timestream has the ability to track measurements across a variety of dimensions, which allows for much more interesting usage of captured data.
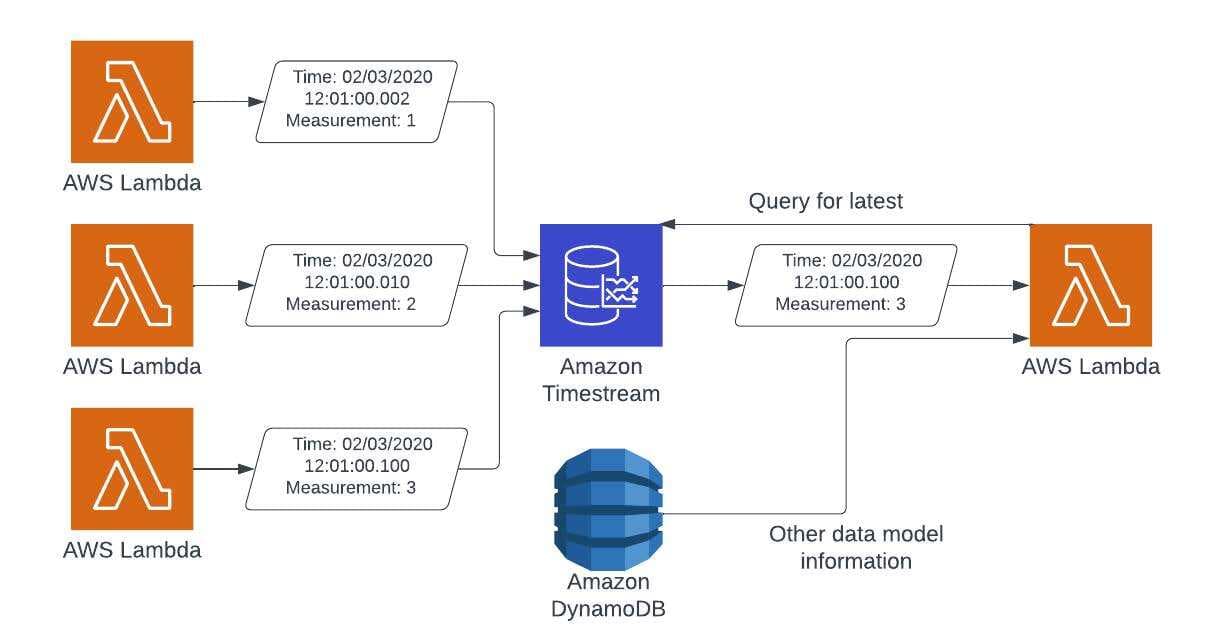
Think about an IoT system that tracks temperature. Amazon Timestream can store this information, along with the customer, the location, the type of device, etc. This allows not only the latest value to be retrieved, but can allow statistics to be generated across devices, timeframes, customers, etc. Amazon Timestream also allows data that is old to be moved to less expensive storage or removed altogether. The reason Amazon Timestream improves performance is that since you’re writing time-based data, the order in which the data comes into the system is less important, and Amazon Timestream will automatically handle duplicate data, eliminating that from the code. This, along with Amazon Timestream’s scaling, allows your system to operate at the highest speed possible, and no longer worry about ordering operations.
If your system has a low amount of writes and a high amount of reads, then you’re probably better off keeping the data in your NoSQL database. Here, you need to decide how important accuracy is. If the data is regularly coming in and slightly older data is set, the system will theoretically heal itself with the next set of data. If that is the case, then your system should move to updating the record property, rather than the full record. This allows you to write at high speed while eliminating the check to see if others are writing to other fields in the object. This will then allow more processes to operate with less record level contention and allow faster overall throughput.
Not all processing updates the same data at the same time in a lot of systems. When dealing with multiple sources of data processing, it's more often than not that the updates are for a specific part of the data model, and not the whole thing. This scenario opens up the door to do partial updates to the object, where your system validates that the original values are present before committing the update. Tools like DynamoDelta make this process simpler, as it takes the guesswork out of how to build the Amazon DynamoDB-specific query and simplifies using this approach more frequently.
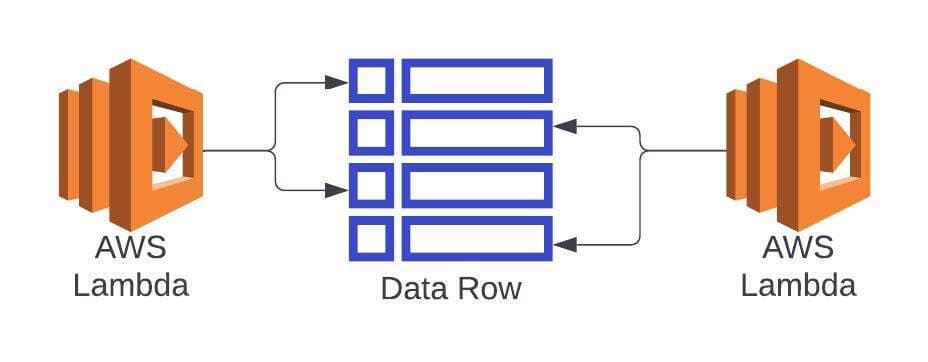
If you have a scenario where an array in your data model is constantly being changed, that is your primary point of contention. In this case, having the array as separate records allows those records to be modified independently from each other, additions and deletions can happen without having to field level considerations, and there’s also some benefit to throughput if done right. With the records being stored separately, there is some data assembly when retrieving them, but in this situation the improved performance of eliminating contention at write more than makes up for the extra effort in the read. This approach can often be seen in Single Table Designs in Amazon DynamoDB, which helps optimize the retrieval options.
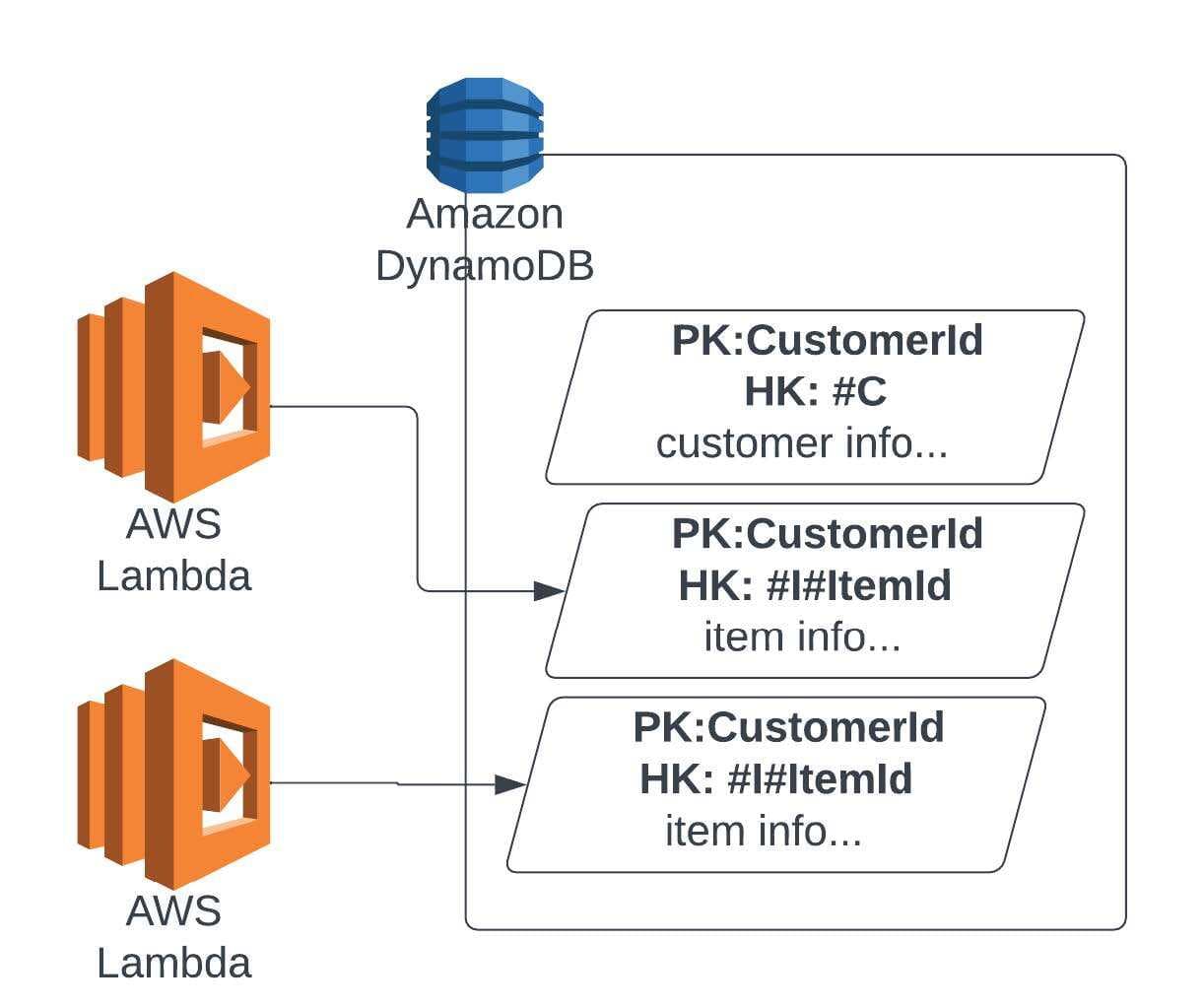
While there can be a lot of reasons why a system will struggle to scale, the problems concerning data are usually related to your data models and how you protect them. In order to extend these systems, you first have to question the approach you store data, and then you can find ways to break through.

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.







