


Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.

Mon, 08 Oct 2018
Serverless is the rare technology that gets business leaders just as excited as engineers. That’s because (surprise!) it’s not really about technology at all. At its heart, the serverless movement is a radical transformation of your business processes and culture to re-orient your business around building value, not dead weight and “keeping the lights on”. In this post, I’ll highlight some of the keys ways we’ve seen that value realized while building serverless systems for our clients here at Trek10.
The number one business advantage of serverless that I tend to hear clients raving about is the decreased time to market.
Serverless speed is how shops like iRobot can manage millions of connected devices with fewer than ten engineers. At Trek10, we routinely build large systems in just days or weeks, using only a couple of dedicated engineers, that would have taken us months to build with larger teams using any other technology. That’s not because we’re awesome (although we’d like to think we’re a little awesome), but because the technology abstraction allows us to focus on building just the pieces of code and configuration that are providing truly unique value for the client.
All that speed would be enticing even if it came at an exorbitant cost. What sometimes startles our clients even more is how affordable a serverless system is.
Of all the names we could have picked to describe this movement, “Serverless” might be the worst: it’s buzzword-y, non-informative, and guaranteed to create arguments. Because yes - we get it, there are still servers in serverless. When I use the term throughout this post, I’ll be referring to technologies that fall in the sweet spot at the center of the diagram pictured below:
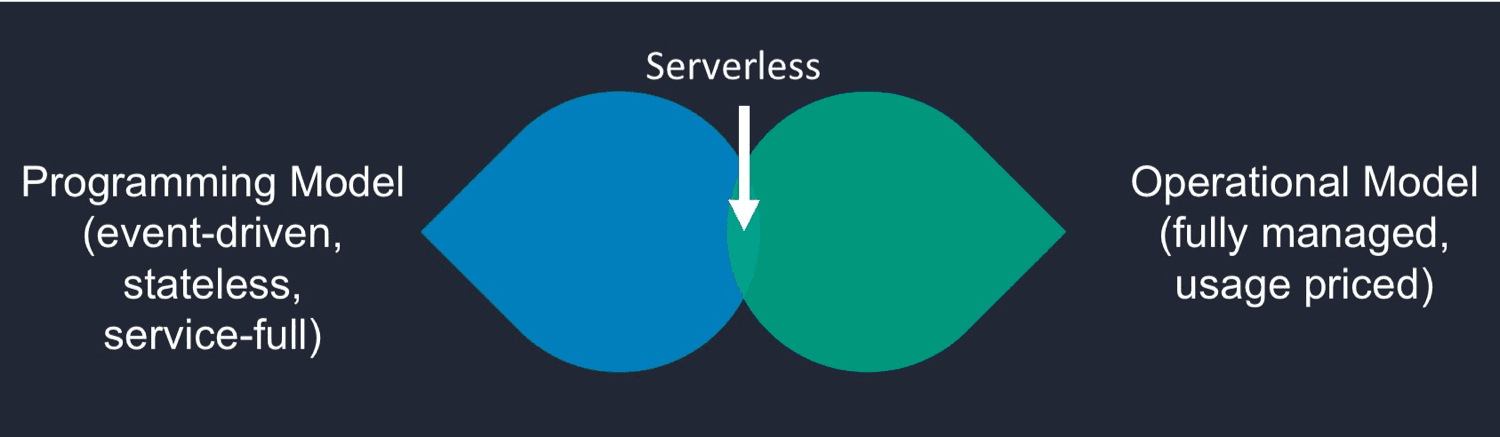
When evaluating a “serverless” technology, you have to look at two facets: the operational model and the programming model. The programming model — functional, event-driven, stateless compute — is typified by “Functions as a Service” providers like AWS Lambda. The operational model — never pay for idle, and don’t manage any infrastructure — can apply to a wide range of technologies beyond just FaaS. Think “managed backends as a service” like Firebase or AWS AppSync.
Note that a technology can utilize parts of the programming model alone (“self-hosted FaaS” options like Kubeless and knative come to mind), or parts of the operational model (managed services that charge for idle, like AWS’s hosted Elasticsearch service), but the closer you are to the sweet spot in the center of the diagram, the more you’ll benefit from the “serverless” advantages we’ll discuss below.
At its most basic, the cost case for serverless boils down to utilization. You’ve probably seen the numbers — traditional, on-premise datacenter servers tend to be only 15 to 30% utilized. (We’ve even heard that most large EC2 users struggle to reach this utilization rate as well!) Put the other way, that means 70 to 85% of your server costs are dead weight. Waste.
Running snippets of code as functions, assuming you have time to re-architect your application so it can do that, can theoretically smooth out that utilization graph so that cost increases linearly with scale. We’ve shared this diagram with our Trek10 clients for years:
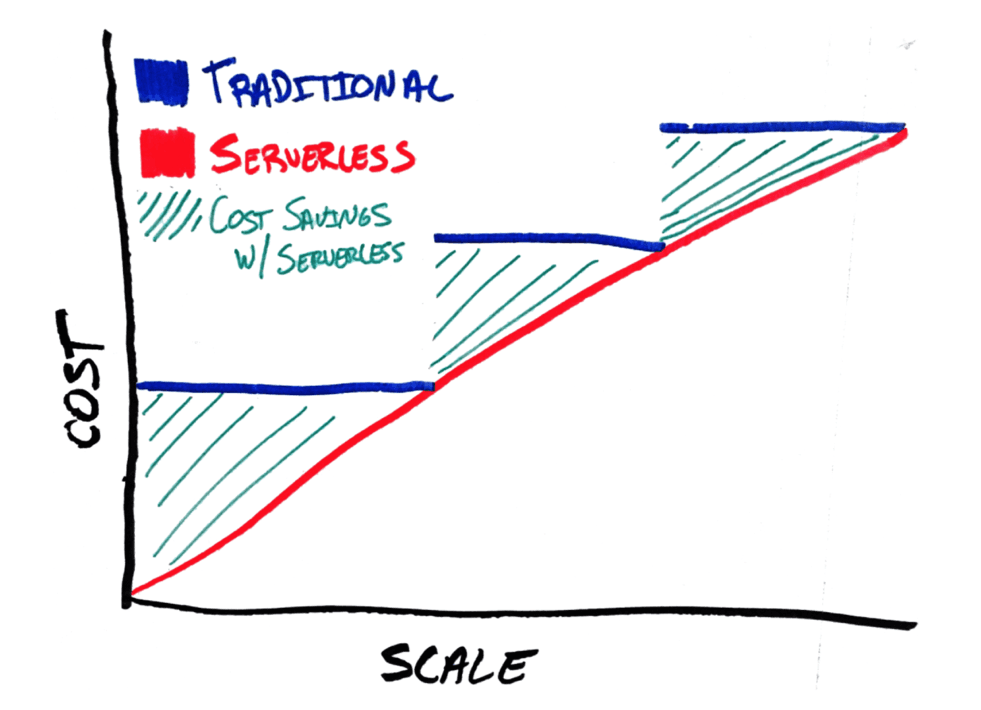
The green dashed lines indicate cost savings in the serverless model, compared to scaling out server capacity. It’s important to keep in mind, too, that the direct EC2 vs Lambda comparison above is a bit apples to oranges. You get a whole bunch of additional services thrown into a FaaS like Lambda:
All those things will cost you additional money in a “traditional” cloud architecture. In a FaaS, they’re just part of the single per-invocation charge. Tim Wagner, the former general manager of AWS Lambda, estimates that the switch to FaaS yields between 4:1 and 10:1 cost compression for a typical enterprise workload.
That’s the straightforward economic argument for serverless, and often it’s enough. But it does bring up what I think of as “the pizza problem”. You may say: “I get that running functions instead of servers, or paying the premium for some other managed service, may save money in small doses. It’s like buying a single slice of pizza. But at large scale, serverless makes about as much sense as buying eight individual slices of pizza instead of a whole pie. The markup kills you. Surely it’s more economical at that point to run servers?”
This point may be correct … as far as it goes. (The website servers.lol has a nice calculator that can help you find the exact inflection point where your Lambda function would cost more than an EC2 instance.) But at Trek10, we’ve found that weighing functions and servers on opposite sides of a scale is a naive way to look at serverless costs. That’s because infrastructure spend is just the tip of the iceberg when it comes to a system’s total cost of ownership, or TCO.

A while back, I was helping someone make a decision about a logging stack for a new service. They had done the math and figured out that they could spend, let’s say, $100k per year on a managed service like Datadog or Splunk. Or they could roll their own logging stack using open source software like Elasticstack, host it on EC2 in their own AWS account and spend something like $60k per year on infrastructure and storage — a 40% savings.
Seems like a clear win for the homegrown approach, right? Not so fast. The “above the waterline” costs for the managed service may well be higher up front, but the TCO for the homegrown approach has barely started. Consider the following questions:
Finally, and most importantly, what else could your team have been doing with all the time spent dealing with the above issues? You hired them to be domain experts on your unique business needs. There’s nothing unique (nothing “differentiated”, to borrow a term from AWS) about that logging stack. Why not have your team focus their valuable time and expertise on creating value for the business?
The build-versus buy calculus can seem overwhelming, but here at Trek10 we’ve had success with Simon Wardley’s unique, freely-accessible method of business mapping. Creating a topographical representation of your business landscape can help you figure out what services to outsource, which to keep in-house, and a whole lot more. Check it out!
If this post is starting to sound less like a case for serverless and more like an argument for adopting managed services whenever possible … well, that’s intentional, and in line with the definition of serverless (some would say “service-full”) that I explained above. But it also raises the ugly specter of vendor lock-in. It’s reasonable to ask what risk we create when we depend on a cloud provider or other third party for key components of our business infrastructure. What if they raise their prices, or deprecate a service, or even go out of business?
I’ve addressed the lock-in question at length on this blog before, so I won’t go into it in too much detail here other than to say: you need to figure out what your biggest risk truly is. Do you partner with a trusted vendor like AWS, that has shown a historical commitment to lowering prices and maintaining services? Or do you stay locked in on legacy technology while your competition leaves you behind?

No. Remember, going serverless isn’t just a technical problem. It’s even more about transforming your organization.
All that stuff I said about engineering hours needed to maintain a traditional system? It can take lots of hours to migrate a legacy system to serverless, too. If you have a product that’s already profitable and well-architected, maybe now isn’t the time to rock the boat. If your engineering team will need a lot of training before they’re productive with serverless technologies, maybe don’t target a serverless architecture for the next tight deadline.
But there isn’t any long term advantage to sticking your head in the sand. The economic advantages of serverless are difficult to ignore, and embraced by an increasing number of companies. Did you know that 90% of AWS’s largest customers use Lambda? Or that 60-year-old credit score giant FICO used serverless to decrease their cloud spend by one to two orders of magnitude?. That could be you. It should be you.
Serverless adoption is going to look different in startups or greenfield products compared to large enterprises with lots of legacy systems. I like what Verizon’s Rajdeep Saha has to say about building a serverless culture that sticks in a big company. I’ll just add a few tips from my own experience:
And, of course, you can follow Trek10 for help with any of this. We’d love to chat with you about ways that serverless can help you — and your engineering team — build useful stuff. Happy building!

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.



