

Spotlight
Guidance for Technical Leadership
A brief exploration of evidence-based approaches to Technical Leadership and Performance Evaluations.


Note: The code references in this post are all updated for version 0.12.x.
Here at Trek10, we see many approaches to consuming the cloud. Of course, Hashicorp Terraform shows up from time to time. There are some exciting things people are doing with Terraform, but we do see some patterns in areas that are not well understood and opportunities for improvement. In this Terraform beginners guide, I'll share common problem areas and often misunderstood behavior that we coach and train internally.
We should start by baselining primary Terraform concepts before moving into a prioritized checklist for readiness.
Terraform is designed around the idea of pluggable providers (written in GoLang) to facilitate the use of the tool for many platforms or systems. The provider is the primary dependency of your project; it creates and manages resources. You can use more than one provider at a time. You want to make sure you are using the same version as the code has been tested or ran with previously. Once you have executed a Terraform project, it captures the provider version to your terraform.tfstate file to make this easier. We’ll explain how remote states help you stay in sync with your teammates later in this post.
Objects defined in your Terraform code that will generate infrastructure in your provider. Resources can be physical objects or logical representations or collections. When you define a resource block, you supply the resource type and provide a name. By convention, the source provider name prefixes the resource type. Within the resource block, you define the configuration for the resource with a set of arguments.
Use modules, use them a lot. They are a fundamental building block for using Terraform properly. They allow you to take a collection of resources and uniformly build them. You define the parameters required, and the outputs returned. I do recommend taking some time when it comes to naming your outputs to find something easy for people to reference and build upon uniformly.
Here I’m using a module to create a group and attach a set of users in a single call:
Calling the module
$ cat users.tf
variable "iam_users" {
type = list
default = ["aaron","brenden","jared","lucas"]
}
resource "aws_iam_user" "iam_user" {
for_each = var.iam_users
name = each.value
}
module "groups" {
source = "./modules/groups-with-users"
group = "kernel"
users = ["aaron","brenden","jared","lucas"]
}
Module definition
$ cat ./modules/groups-with-users/variables.tf
variable "users" {}
variable "group" {}
$ cat ./modules/groups-with-users/main.tf
resource "aws_iam_group" "iam_group" {
name = var.group
}
resource "aws_iam_group_membership" "group_attachment" {
users = var.users
group = aws_iam_group.iam_group.name
}
$ cat ./modules/groups-with-users/outputs.tf
output "group_arn" {
value = aws_iam_group.iam_group.arn
}
When you execute terraform plan or terraform apply, Terraform creates a dependency graph from all files matching *.tf in your current working directory. Keep in mind, the files ingested are only in your current directory. There is no recursion into sub-directories, but you can use this to group your resource definitions logically to make development and troubleshooting tasks easier. For those more familiar with CloudFormation this would be similar to generating a composite template from multiple files before running. It is different from CloudFormation nested stacks because changes are applied to the whole set, not sub-templates. If you need further control, use modules, or split resources into many projects.
If you run into a situation where the graph improperly resolves execution order, there is a depends_on flag to force ordering. While improved in 0.12 there may still be edge cases where depends_on still has difficulties when referenced between modules.
When you perform $ terraform plan -out=./out.tfplan you generate an execution plan. This can be used as an input for a subsequent $ terraform apply ./out.tfplan to ensure Terraform will only execute if the environment is still in sync with what was observed during the last plan. This is important when you have many contributors to a project or you want to leverage a Terraform CICD pipeline and would like a convenient and safe way to review changes.
When you ask people what they like about Terraform, in the top 5 is how easy it is to tell what will happen as a result of your actions. In this example, you can see a snippet of resources that would be created if we were to apply these changes.
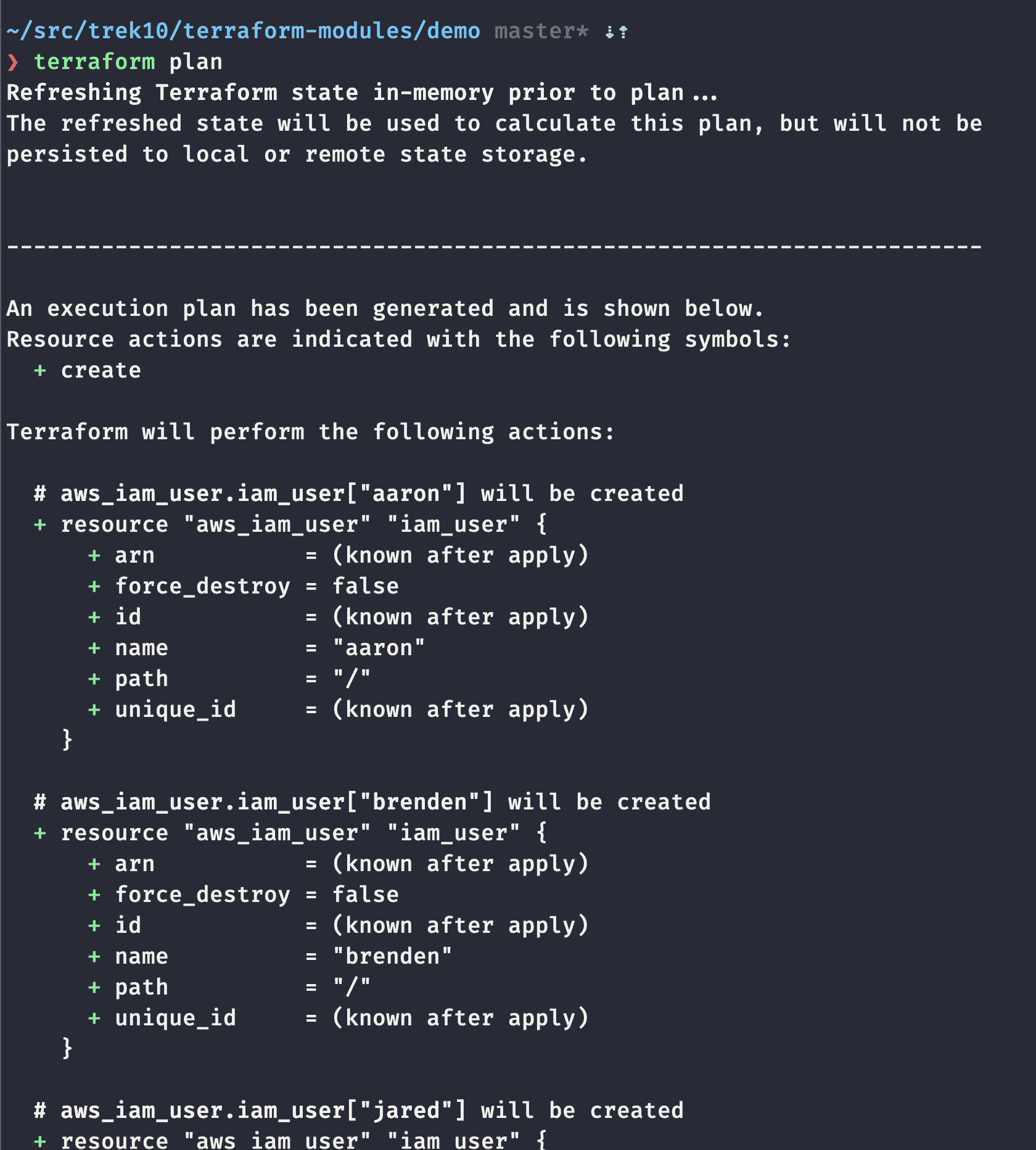
Followed by more output and finally the summary:

To make Terraform AWS works, Terraform needs a mechanism to know what resources in the target AWS account belong to your current project and which do not. Terraform records the list of resources and their attributes when you perform $ terraform apply. It then compares your current code (the request) with the target account (current state) and with its last known state (your terraform.tfstate file).
If you have a project managed by Terraform, do not perform manual changes (via console/api/etc)! Capture all your changes as code, the extra effort is worth it, and not doing so invalidates a lot of the benefits of infrastructure as code or worse ( https://charity.wtf/2016/03/30/terraform-vpc-and-why-you-want-a-tfstate-file-per-env/ ).
A state is considered remote when you are using the state generated from one project from another project. Terraform allows you to use outputs within your stack to give well-known names to specific values. When you leverage those values between stacks (generally as parameters), you are using remote states. These are very powerful and one of the methods for loosely coupling components. Consider separating your account "readiness" actions of setting up base infrastructure, logging, security, VPCs from your applications deployed into this environment. Export values for App stacks to consume with consistent naming, and you can make your apps very portable while allowing developers to stay focused on their priorities. In AWS we’ll typically use S3 as the remote state store, you’d reference it like this:
data "terraform_remote_state" "global" {
backend = "s3"
config {
bucket = var.state_bucket.bucket_name
key = 'global/terraform.tfstate'
region = var.state_bucket.region
}
}
And assuming this remote state outputs a value for state_bucket.name use it like this:
s3_bucket_name = data.terraform_remote_state.global.state_bucket.name
This post defines Need, Want, Nice to Have categories to help you prioritize your efforts.

Store your Terraform project in version control, something like Git.
You should never commit secrets to your version control, this should include your .tfstate and .tfstate.backup files. I use a service called gibo to make this painless. It becomes as easy as gibo dump terraform >> .gitignore.
Alternatively, you can just add the following to your .gitignore manually.
# Local .terraform directories
**/.terraform/*
# .tfstate files
*.tfstate
*.tfstate.*
A word on secrets and git: If you are worried about committing secrets (or regularly have "accidents") , I'd highly suggest checking out AWS' git-secrets project. An open-source, fairly robust way of preventing unfortunate git commits.
It might be tempting to pass your certs, tokens, keys, passwords, and other sensitive data out through Terraform because of convenience. Avoid this as the data passed in can be caught in your .tfstate file. AWS offers services you can use to distribute secrets, certs, and such to your resources. Look at AWS Systems Manager Parameter Store you can distribute roles to your resources that allow them to get these secrets in an easy/secure way!
When using remote modules, they should be versioned.
If the remote source is a git repo, you can reference a tag or commit SHA in the remote location call. You should do this as it allows you to change your module upstream and still have control over releasing changes per application. Versioning looks like this:
module "local" {
source = "git::ssh://git@github.com/trek10/terraform/tf-mod-vpc.git?ref=0.1.4"
...
}
The Terraform Registry is a public module registry provided by Hashicorp. You can also self-host private registries. Though in our experience, if you can't use the public registry, using git is less overhead. If you a source that uses the module registry protocol you use it like this:
module "local" {
source = "trek10/terraform/tf-mod-vpc"
version = "0.1.4"
...
}
Resources provisioned are captured to a state file (*.tfstate); when making actions on resources, this file read. If the Terraform definition specifies a resource not found in the state file, it tries to create it. Similarly, if you try to destroy a resource that is in the state file and deployed, you get a warning as being out of sync. The proper way to manage state is to use a Terraform Backend, in AWS if you are not using Terraform Enterprise, the recommended backend is S3. If you have more than 1 person working on the same projects, we recommend also adding a DynamoDB table for locking. Please enable bucket versioning on the S3 bucket to avoid data loss!
Note in this code we referenced the resources that we are creating. This creates a circular dependency, so you must execute this twice; once to create the resources, a second time to enable the remote backend. For the first execution, you must comment out the `backend "s3"`.
terraform {
required_version = ">= 0.12.0"
backend "s3" {
bucket = "bmls-tf-state-bucket"
key = "base"
region = "us-east-1"
dynamodb_table = "terraform_lock_table"
}
}
provider "aws" {
region = var.region
}
resource "aws_s3_bucket" "state_bucket" {
bucket = var.state_bucket.bucket_name
acl = "private"
versioning {
enabled = true
}
}
resource "aws_dynamodb_table" "terraform_lock_table" {
name = var.state_bucket.dynamodb_table
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}

Terraform gives you the flexibility that is great when you are an advanced user but can be a bit overwhelming when getting started. You know you want to stay DRY, achieve high parity, and you want to leave something easy to troubleshoot when you've not touched it for 12 months, but you don't yet know how your project is going to grow.
Many of the examples available show mono repositories with folders per environment or even folders that map to accounts, regions and availability zones. I'm going to recommend avoiding these patterns as it creates a big opportunity for human error when making changes. What happens when you forget to update a zone or region?
Right now (change my mind) I have 2 meta patterns I use depending on where the project is in the cloud-native journey. In either case, I highly leverage modules.
/scripts/ is where I stash scripts, tools, and configurations
/modules/ is where all my module definitions are stored, generally, these are individual repositories but they still work if you go mono-repo just use local pathing to reference them instead
/network/ has a few projects within it for 1-time deployment items that don’t have multiple target environments
master-payer is my root account configurationmaster-iam is an account for IAM user definitions, we’ll use cross-account roles instead of generating users in each account.master-security is a limited access account buckets and tooling for my logsshared everyone ends up with a shared account, this is mine, I’ll make projects within it for different tooling that is stood up here. Depending on how you handle domain names, you may put your root zone definition here though I generally put that in my /apps/ prod workspace.├── apps
│ ├── app-stack-1
│ │ ├── app
│ │ ├── data
│ │ └── etc
│ ├── app-stack-2
│ │ ├── app
│ │ ├── data
│ │ └── etc
│ └── multi-tenant.tf
├── modules
│ ├── tf-mod-3-tier-app
│ ├── tf-mod-s3
│ └── tf-mod-vpc
├── network
│ ├── master-iam
│ ├── master-payer
│ ├── master-security
│ ├── shared
│ │ ├── monitoring
│ │ └── security
│ └── transit
└── scripts
In more traditional environments I generally see “dev”, “stage”, “prod” accounts (or something similar) with a shared VPC with or without many subnet groups that is home to application instances. I do that here with /apps/ by leveraging workspaces. I’ll have my multi-tenant infrastructure file to define networking resources (vpcs, subnets, route tables, etc.) along with any other shared components I need to make this account “ready” for application deployment. We will want to export a lot of values here (or write them to SSM Parameter Store) this will help us with our application deployment later. The applications are then deployed “onto” this infrastructure and they will use output values from the multi-tenant.tf stack via a remote-state data object to ensure they are correctly provisioned.
├── app-stack-1
│ ├── app
│ ├── data
│ └── etc
├── app-stack-2
│ ├── app
│ ├── data
│ └── etc
├── modules
│ ├── tf-mod-3-tier-app
│ ├── tf-mod-s3
│ └── tf-mod-vpc
├── network
│ ├── master-iam
│ ├── master-payer
│ ├── master-security
│ ├── shared
│ │ ├── monitoring
│ │ └── security
│ └── transit
└── scripts
For more cloud-native approaches where you may not have a lot of underlying infrastructure, the general practice is to define everything an application stack needs within AWS. Any platform requirements for this app stack should be configuration values that can be retrieved from SSM Parameter Store, AWS Config, etc. In this case, we don’t need to define a multi-tenant infrastructure or perhaps even VPC. If my application needs it, I should define that within the app stack itself. I may want to delineate different components within my app into separate terraform projects (or not) and that can be easily configured at the project level based on its needs.
Naming is a delicate topic that generally causes some divide. Generally, audiences newer to AWS want particular resource names on all their resources so they can "see" items in their AWS console and understand how items are related. Don't worry, this is fine, and part of the learning process to become cloud-native. It's good that you want to understand how everything relates.
Groups that have been around AWS longer, or that are dealing with high resource counts generally want basic/simple identifiers on resources but may rely much more on tagging, operational tools, or interrogating their Terraform stacks to find relationships. This shift primarily happens as teams make less use of the AWS Console for daily work and rely more on CLI, API, scripts, and other methods for managing their accounts.
Whichever your preference, you should incorporate a tagging strategy and leave flexibility in your names so you can avoid dreaded name conflicts. I've certainly been a victim of this; it's much too easy to do in Terraform, so design around it from the beginning!
Moving your Terraform deployment process away from your machine and into a managed pipeline has merits.
Thankfully this process is well known, and there are templates/boilerplates out there for you to borrow. Generally, the pattern should look something like this:

A few notes on how this is built:
$ terraform plan -out=./out.tfplan in your pull request reviewThis describes Workspaces as they behave in Terraform CLI if you are using Terraform Cloud the behavior is different https://www.terraform.io/docs/...
Workspaces are superior to keeping project copies (in the same repo or different) use them! https://www.terraform.io/docs/state/workspaces.html You are already using the default workspace without ever specifying it. Extend this default workspace by creating workspaces to match your SDLC. You want high parity between your dev and prod environments; this makes that easy:
$ terraform workspace new dev
Created and switched to workspace "dev"!
$ terraform workspace new stage
Created and switched to workspace "stage"!
$ terraform workspace new prod
Created and switched to workspace "prod"!
$ terraform workspace select dev
Switched to workspace "dev".

Most popular editors have plugins for Terraform/HCL linting. We find these very helpful and recommend installing and using them. I use the following extensions with Vscode:
Name: Terraform
Id: mauve.terraform
Description: Syntax highlighting, linting, formatting, and validation for Hashicorp's Terraform
Version: 1.4.0
Publisher: Mikael Olenfalk
VS Marketplace Link: https://marketplace.visualstudio.com/items?itemName=mauve.terraform
Name: Advanced Terraform Snippets Generator
Id: mindginative.terraform-snippets
Description: Provides 550+ code snippets of Hashicorp's Terraform cloud orchestration tool.
Version: 2.1.0
Publisher: Richard Sentino
VS Marketplace Link: https://marketplace.visualstudio.com/items?itemName=mindginative.terraform-snippets
The Terraform version manager project (https://github.com/tfutils/tfenv) is beneficial if you have many terraform projects that you manage. For those not familiar with version managers, it's a simple tool that allows you to install and use multiple versions of Terraform.
For extra convenience and speed, make Terraform auto-select the correct version for you. Great when collaborating with others to help them not stub a toe.
$ echo "0.12.23" >> .terraform-version
Follow the instructions to set it up; the magic happens by intercepting calls via simple $PATH manipulation.
Many groups find it beneficial to wrap Terraform execution with scripts to save time and add safeguards. Examples may be enforcing $ terraform plan before $ terraform apply or selecting the appropriate workspace. I find it helpful to accelerate team members less familiar with Terraform so they can get started quickly without having to learn when and why they need to call $ terraform init. Here's a simple example:
#! /bin/bash
terraform init
# expect a warning, don't worry it's an idempotent operation
terraform workspace new dev
terraform workspace select dev
terraform plan

A brief exploration of evidence-based approaches to Technical Leadership and Performance Evaluations.





