
Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


Step Functions are great for controlling flow in long-running serverless workflows, but also come with limitations. In this post we’ll explore what makes a project a good fit for Step Functions.
One of the first experiences I had with Step Functions was in a first draft design for a flexible IoT platform with reusable pieces built on top of AWS IoT. After creating a cost model spreadsheet, it was quickly decided to change the design to simply use AWS IoT Core Rule Actions. For this particular use case, it just made more sense to keep the data flow decisions within AWS IoT Core. Between easier control and cutting the cost of the data flow in half, it just made sense. So when is the right time to use Step Functions? First, let’s talk about how we define Step Functions.
Warning: if you already have Amazon State Language experience then you can skip this bit here
Step Functions are defined using Amazon State Language, which is made up of three main states. The main three states for the Amazon State Language are Task, Choice, and Fail. On the surface, these are simple but can be composed into large workflows and remain easy to reason about.
Here is an example of what Amazon State Language looks like, essentially JSON.
{ "Comment": "An example of the Amazon States Language using a choice state.", "StartAt": "FirstState", "States": { "FirstState": { "Type": "Task", "Resource": "arn:aws:lambda:us-east-1:123456789012:function:FUNCTION_NAME", "Next": "ChoiceState" }, "ChoiceState": { "Type" : "Choice", "Choices": [ { "Variable": "$.foo", "NumericEquals": 1, "Next": "FirstMatchState" }, { "Variable": "$.foo", "NumericEquals": 2, "Next": "SecondMatchState" } ], "Default": "DefaultState" }, "FirstMatchState": { "Type" : "Task", "Resource": "arn:aws:lambda:us-east-1:123456789012:function:OnFirstMatch", "Next": "NextState" }, "SecondMatchState": { "Type" : "Task", "Resource": "arn:aws:lambda:us-east-1:123456789012:function:OnSecondMatch", "Next": "NextState" }, "DefaultState": { "Type": "Fail", "Error": "DefaultStateError", "Cause": "No Matches!" }, "NextState": { "Type": "Task", "Resource": "arn:aws:lambda:us-east-1:123456789012:function:FUNCTION_NAME", "End": true } }}Amazon States Language Concepts
Here are some AWS Use Cases for Step Functions
The examples that AWS has here are great, but pretty specific. What do they all have in common? A few patterns that I discovered for Step Functions were:
Given a use case that only fits one of these patterns you may be able to find a less expensive way to design without Step Functions. Once you have more than one of the patterns in your design, it is a good chance that Step Functions your best bet. Let’s dive a little deeper into what these patterns are so that we recognize them in your use cases.
This pattern is about making decisions with the control of your state machine. Let’s look at the Transcode Media Files example given to us by the AWS Step Function Use Cases.
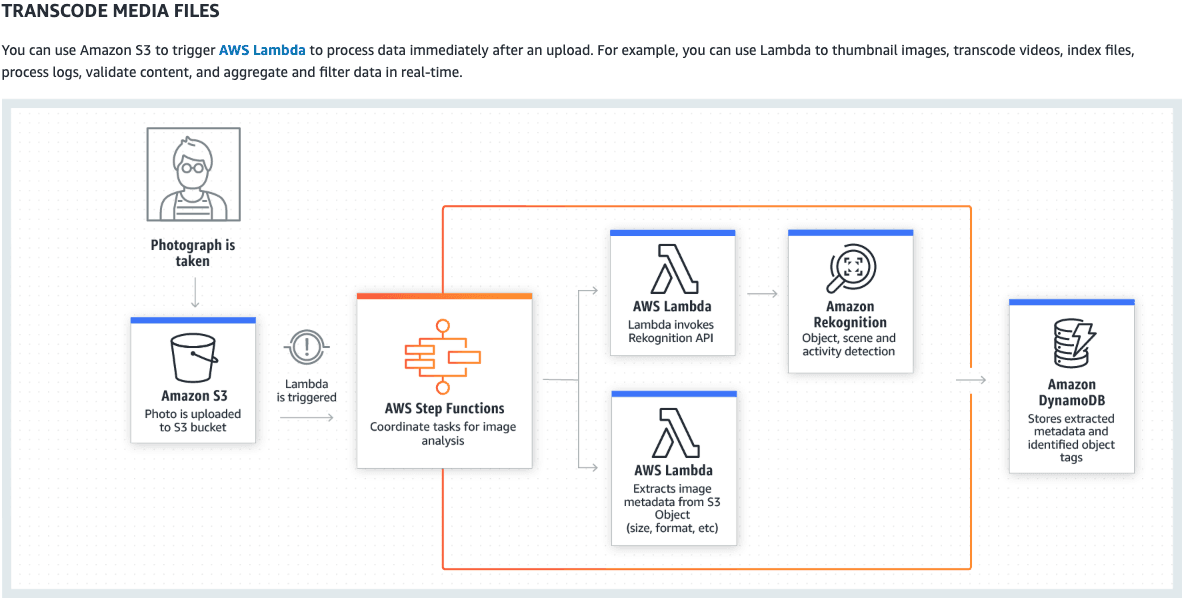
In this example, we see that when a photo is uploaded to S3 a Lambda is triggered to start the execution of a step function. Once in Step Functions, the job splits the workload into one lambda for extracting metadata from the S3 object and another for running using Amazon Rekognition for the object, scene, and activity recognition. The results of all of this are stored in DynamoDB. Why is it so important that we split the workload into composable parts? Couldn’t we have just as easily put all of this into one function that would all of these steps in one? Yes, but we would lose control of the flow and reusability of the code/function.
The Lambda that extracts metadata could be used in other projects. We can treat this metadata extraction like a microservice that could be used by many applications. When we have functions that are being treated like a service, then we need glue to bind these services together, that glue can be Step Functions. These services are going to fail and we need to be able to recover from that failure, this leads us into our next pattern.
As we stitch reusable services together for multiple application, failure is bound to happen. With AWS Lambda, we are bound to 15 minutes of runtime for a single function execution. We have retry options like Dead-Letter Queue but what if you need something radically different for when your lambda fails or times out? If you know it failed because of Lambda timeout, but it was still processing, you could continue the processing on AWS Batch. These actions need orchestration and that is something that Step Functions is very good at. It has functionality for simple retries and backoff retries, as well as branching decision making on the type of failure that happened. Since that decision making is really where the power comes from, I suggest diving deeper into what that language offers.
Link to more detail about handling errors in Amazon State Language here.
This pattern is a little harder to define because of long-running means different things to different organizations. In this case, I am really focusing in on long-running meaning more than what could be run in a single Lambda (15-minute timeout) but also potentially needing manual human interaction. Some important processes just can’t be left to software to decide (or at least not yet). An example that I found for this was an employee promotion process. We still want this type of process to be finalized by humans. The example given could be given with automated processes prior to the final decision. The process might have many automated steps that would set an employee on a promotion path. For someone working with AWS, a new certification could set this in motion and that could be automatically checked but the decision of the manager would ultimately decide. That manager’s interaction might look like the manual approval process given in the link above. Remember that a Step Function invocation can last up to 1 year. For other limits take a look here.
The next time you are looking for an orchestration tool for your serverless project consider Step Functions. You can decide by asking yourself:
If your answer is yes to more than one of these AWS Step Functions may be the tool you need for the project.

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.






