

Spotlight
Guidance for Technical Leadership
A brief exploration of evidence-based approaches to Technical Leadership and Performance Evaluations.


With all of the customer obsession shown by AWS, this pre:Invent has made it quite clear that the developer persona is now clearly in the sights of AWS teams.
Operating under the AWS Systems Manager banner, AppConfig is here to make “it easy for customers to quickly roll out application configurations across applications hosted on EC2 instances, containers, Lambdas, mobile apps, IoT devices, and on-premise”. It seeks to separate the deployment of configurations from the deployment of your code or infrastructure.
The big win of all of this is that no longer are you bound to full-on code deployments to change configuration profiles across your applications. You can safely and quickly execute configuration changes (for instance, feature flags) without risking code-level changes.
The taxonomy of AppConfig is reasonably intuitive, starting with the top level of Applications and Deployment strategies. Each application has two different classes below it — Environments and Configuration profiles. The relationship between the two being that Configuration profiles are applied to environments via deployment strategies.
You may be asking yourself how this is any different than something like Parameter Store, which gives you the capability to poll for configs. Your Configuration profiles are stored in the Parameter store (Advanced tier only) or as an AWS System Manager document.
There are 2 main points of differentiation that make it an exciting choice versus rolling your own with Param Store.
You can add validations as either JSON Schema, a vocabulary that allows you to annotate and validate JSON documents, or by calling out to an AWS Lambda function for more complex validations. You can add one or more validators to a particular Configuration profile.
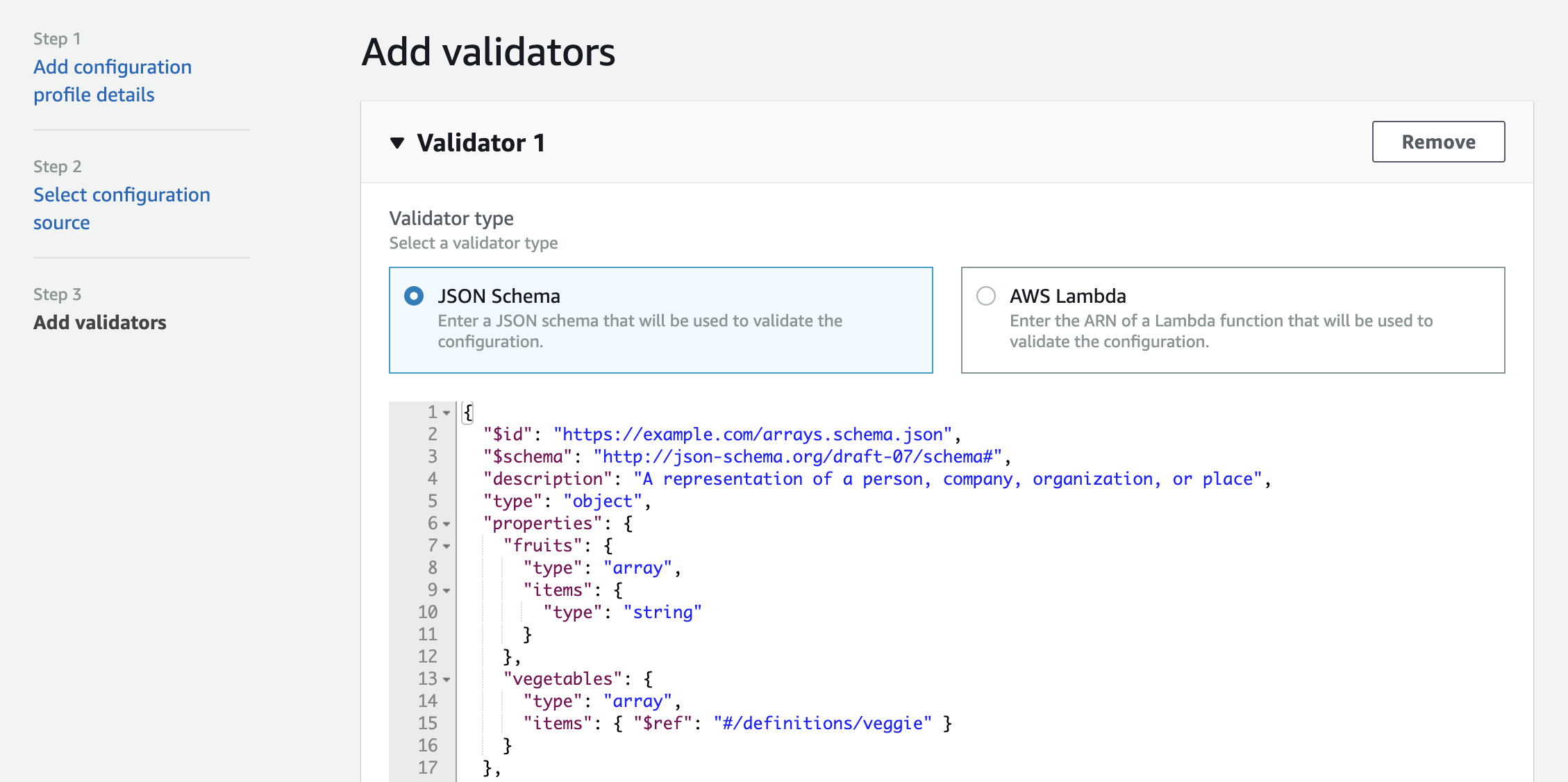
Now, you can update your source config store (Param store or AWS System Manager document) with any values you like. These changes reflect in AppConfig as a config version. However, upon starting a deployment, your validation runs on the configuration version you select. An error blocks deployment in case of failure.
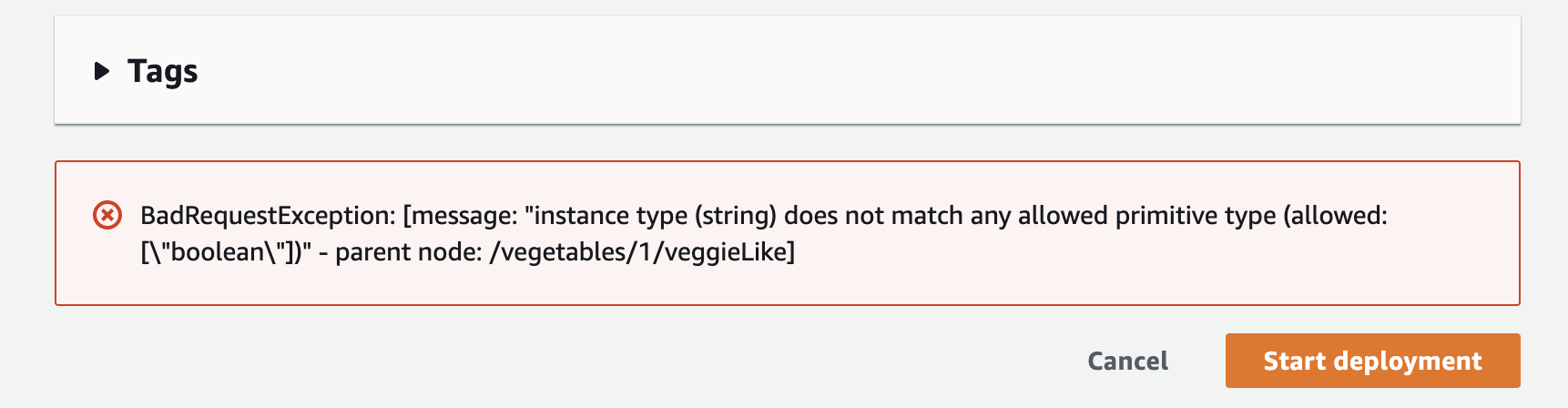
This validation feature is your first line of defense against “oopsie” type mistakes. The balance, of course, being ultra-restrictive vs. agility.
Deployment strategies are how you rollout configuration changes.
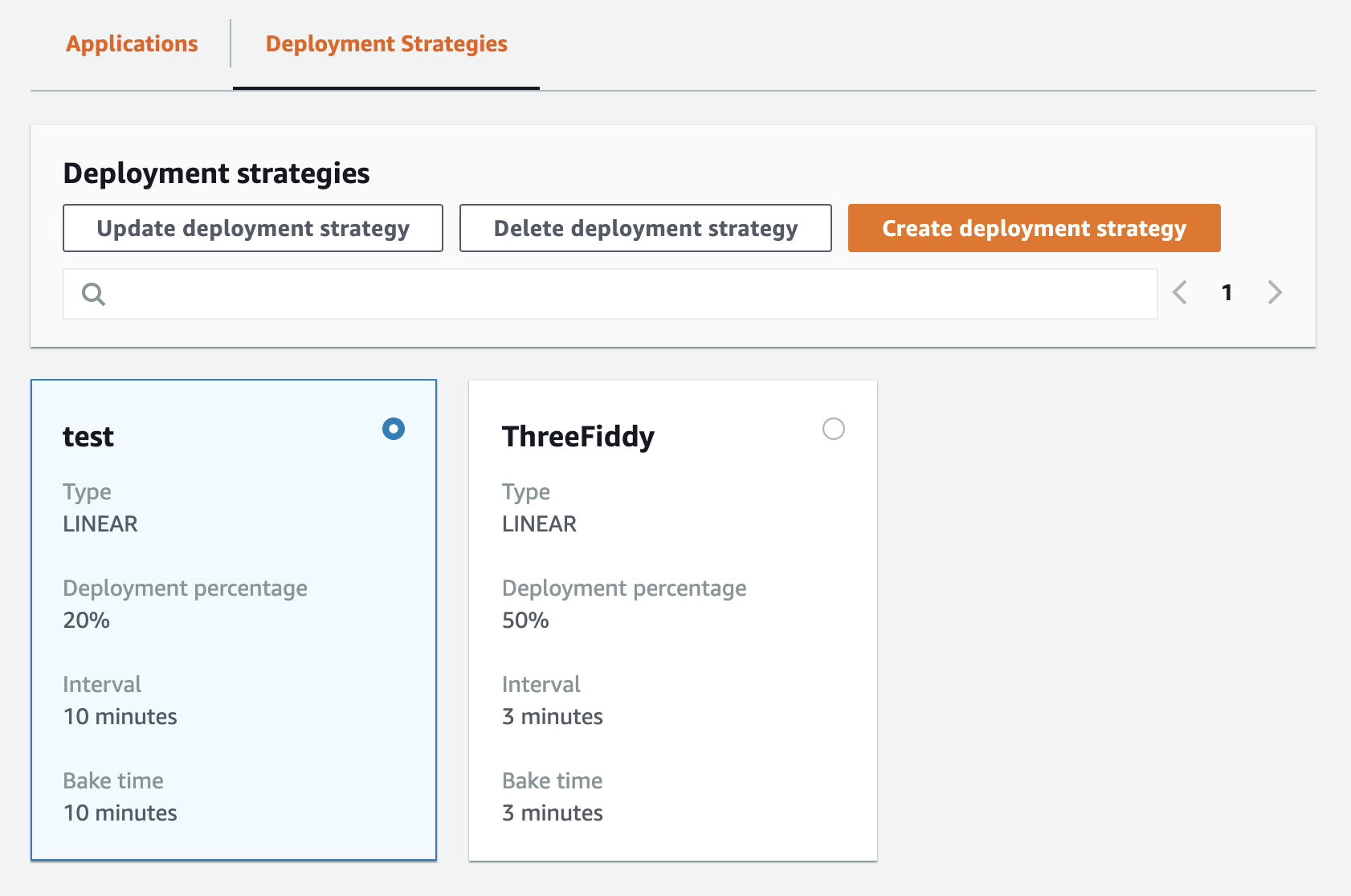
These deployments based on Application and ClientID, along with configured CloudWatch alarms, decide how many clients to roll out a config change to, and continuously decide if things are going well. If not, AppConfig will rollback those config changes for you to the previous working one. Once again, no big code changes to rollback — just config.
From a technical perspective, retrieving the configuration is pretty darn simple. For cost and performance reasons, I would suggest caching this response and only rechecking every so often.
var params = { Application: 'STRING_VALUE', /* required */ ClientId: 'STRING_VALUE', /* required */ Configuration: 'STRING_VALUE', /* required */ Environment: 'STRING_VALUE', /* required */ ClientConfigurationVersion: 'STRING_VALUE'};appconfig.getConfiguration(params, function(err, data) { if (err) console.log(err, err.stack); // an error occurred else console.log(data); // successful response});Now, this gets interesting on how you want to segment your rollout. Your ClientID is what determines the rollout and could be as wide as your entire “application” a pretty big bang config release, as granular as something like unique identifier per lambda function container (ex: CloudWatch log_stream_name from the context), or somewhere in the middle like a function_name. Important note, ClientID’s (targets) updated is a core part of the pricing model.
| Operation | Cost |
|---|---|
| GET API calls to check for a new configuration | $0.2 per 1M GetConfiguration calls |
| Deployment Costs | $0.0008 per configuration update per target |
The only way I can currently find to get the application, environment and configuration ids needed for the SDK calls is from the URL in the console or via the CLI, it is not easily exposed in the console GUI itself. Weird.
If you send a ClientConfigurationVersion in your request, if it is a matching version of the current one the returned config blob is empty (or an empty buffer).
Tags are by far and away one of the greatest tools of cost centers / analysis available to us in AWS today. Not only that, but a growing amount of additional functionality around security and access management is integrating with tags.
However, this leaves a great deal of responsibility on developers to do the right thing. Jeff Bezos points out, “Good intentions don’t work, but mechanisms do.”
WIth Tag Policies, you can now enforce tags and standards for those tags at the organization and account level, requiring tags to be present and optionally have specific values.
There are two different modes of compliance, either warning or blocking non-compliant operations altogether. Want to create a DynamoDB Table without a “env” tag? NOPE. Organizations can also generate reports on compliance at the resource level.
At the end of the day, this is about preventing mistakes before they happen. Developer Experience also means gentle guide rails where possible in the land of compliance is excellent.
If you’ve ever written a lambda function or cron job to ping your server or endpoints, CloudWatch Synthetics takes that to the next level.
It provides a centralized managed way of running “canaries”, small little scrips (via Lambda Function), that can be run once or, more likely, on a schedule.
These canaries can do everything from simple heartbeats to more advanced API testing, link checking, or in-depth user-experience simulation GUI driving.
Your results can share all sorts of useful info like screenshots, HARs, and logs. Great for rapid debugging.
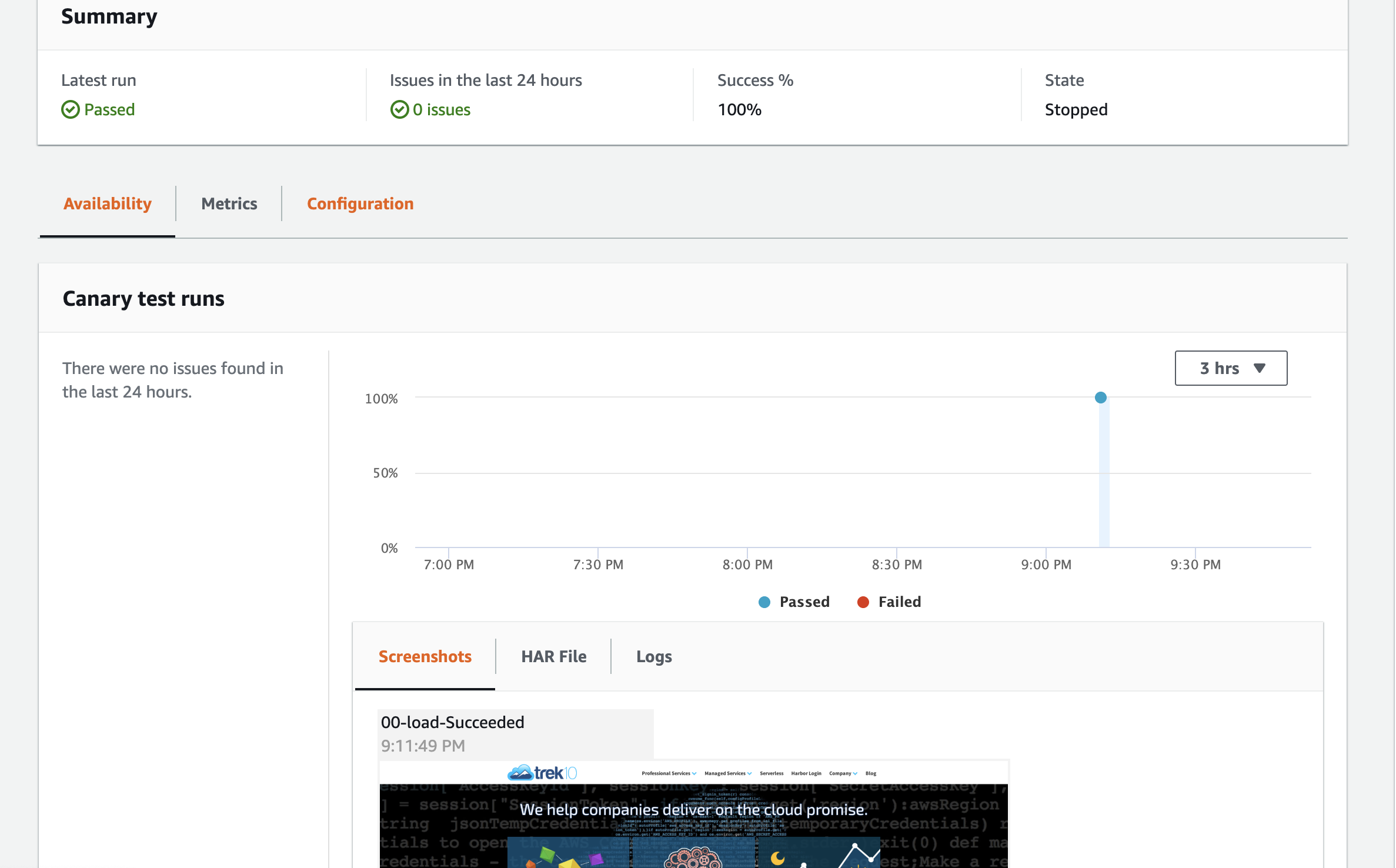
All the information from the runs is recorded into CloudWatch Synthetics and then compared for thresholds and alerting, as well as be applied against X-Ray to understand the client experience vs. your canary. You can even leverage X-Ray Analytics to identify gaps in canary coverage.
CloudWatch Synthetics is available is us-east-1, us-east-2, and eu-west-1 with pricing at $0.0012 per canary run in us regions and $0.0014 in the EU. Presumably, you must also pay the lambda execution cost (this is not detailed in the CloudWatch pricing page or docs).
AWS Amplify is becoming one of my personal favorite “services” in AWS. Scare quotes here because it’s a collection of services, SDKs and a CLI. All of which aim to make building modern, cloud-native web and mobile apps straight forward.
There are a few big things to know about in the Amplify Ecosystem.
A “netlify” type experience with built-in CI/CD for you frontend (and backend) applications. It does some really neat stuff, especially around instant cache invalidation.
Gives developers a rich command-line experience for building and managing mobile and web apps. It integrates directly into Amplify Console, providing a cohesive end to end experience.
Also, the Amplify CLI provides rapid ways to generate AppSync based GraphQL APIs via the GraphQL Transforms.
In short, a suite of SDKs for various targets (web, React, iOS, and Android) to simplify interacting with AWS services (like AppSync and S3), as well as providing some great out of the box authorization UIs.
Some of the tremendous new developer experience stuff recently introduced involves making it easier for teams to work on branches of the frontend application, while iterating against existing versions of the backend. How often do developers just need to add or tweak frontend capabilities (change the UI around a bit, a different button color here, bold that text there.)? With Amplify Console / CLI, they can point to the existing dev backend and iterate away. Are they iterating on a much bigger feature? Create a whole new backend environment, iterate away on your GraphQL API or business logic without getting in the way of everyone else expecting a semi-working dev.
Save a bit of money and time when you can, flexibility for independence when you need it!
Also recently introduced is deep integration with cypress.io as part of the CI/CD pipeline for UI testing, as well as better visibility into the CI/CD process.
This one is just pure Developer Quality of Life improvement. If you are lazy like me, you’ve scripted SAM CLI a hundred time with a simple wrapper that defines your bucket, stack name, region, etc.
No more! sam deploy is smart enough to use (or create) a SAM bucket for you, and you can save your settings in samconfig.toml (learn more) as well for rapid dev iterations.
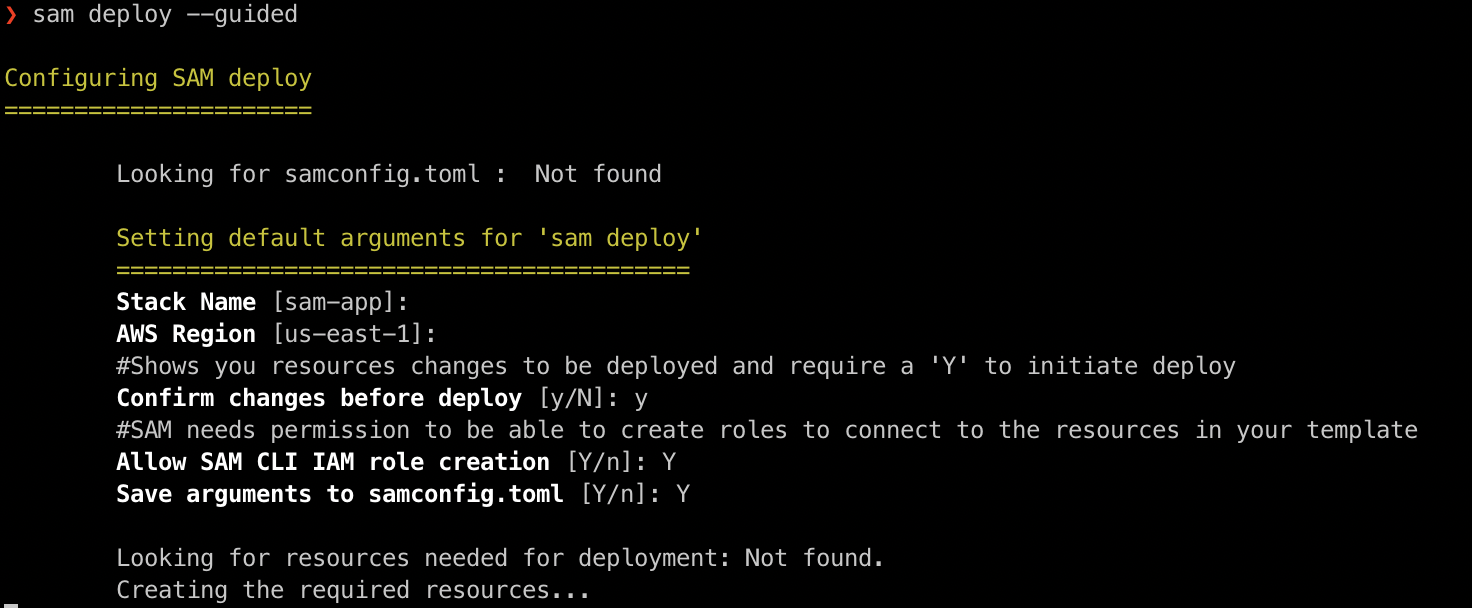
SAM even asks about changesets to make sure you are good with all the changes.
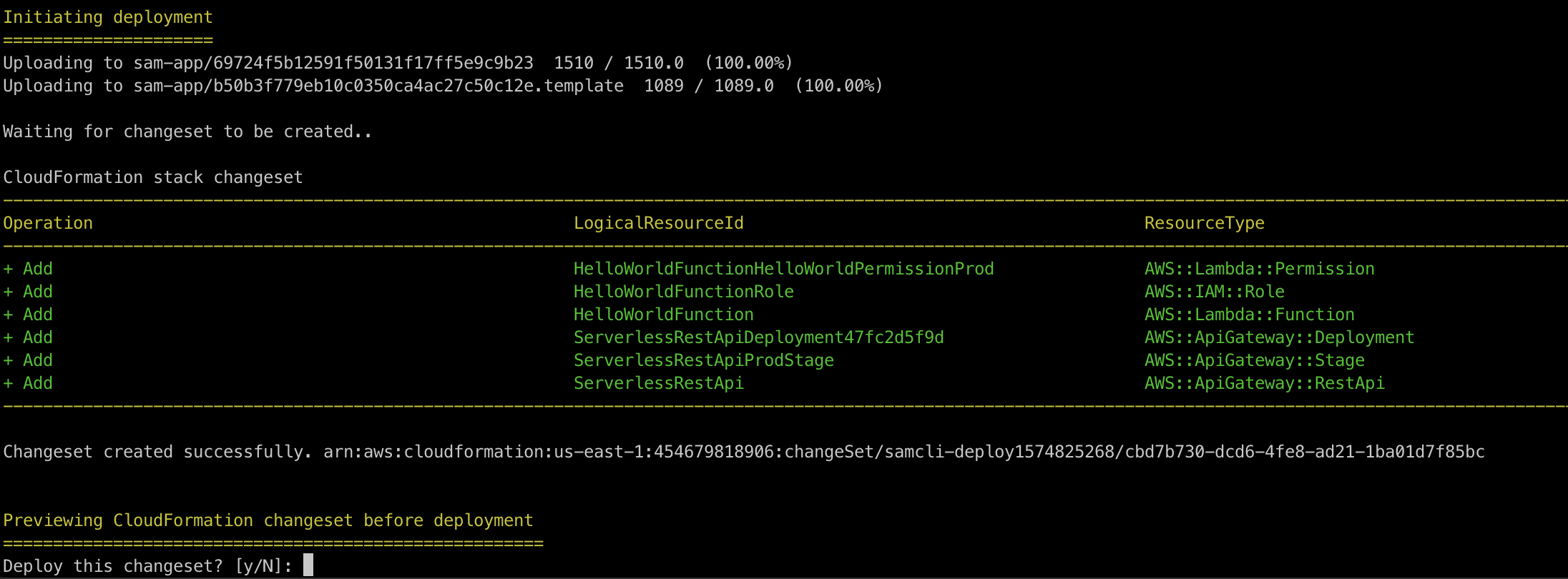
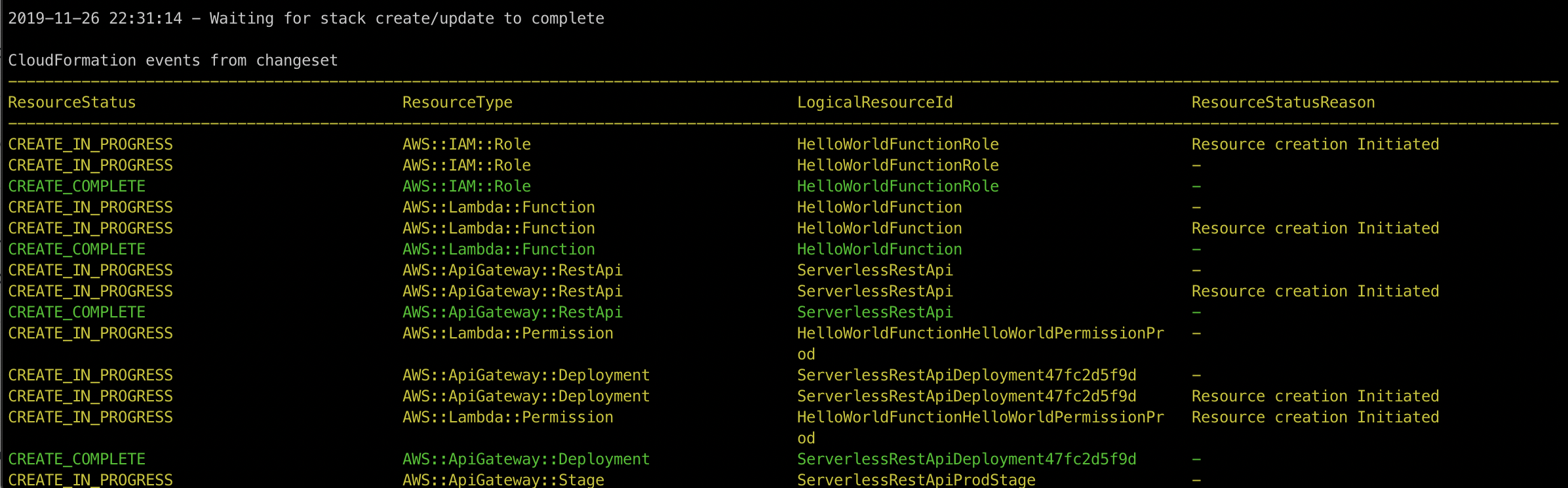
SAM now reports back in realtime your deployment status as well.

A brief exploration of evidence-based approaches to Technical Leadership and Performance Evaluations.







