

Spotlight
How to Use IPv6 With AWS Services That Don't Support It
Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.


One of the most interesting “digs” at serverless lately has been the concept that it isn’t simple. The typical M.O. is showing a complex diagram with lots of arrows and icons, evoking a feeling of overwhelming complexity and hopelessness in ever understanding what is going on. Alternatively, I believe one can look at those very same diagrams and see otherwise implicit business complexity now made helpfully explicit by architecture and functional connections.
Let’s take the example diagram that caused an uproar on Twitter.
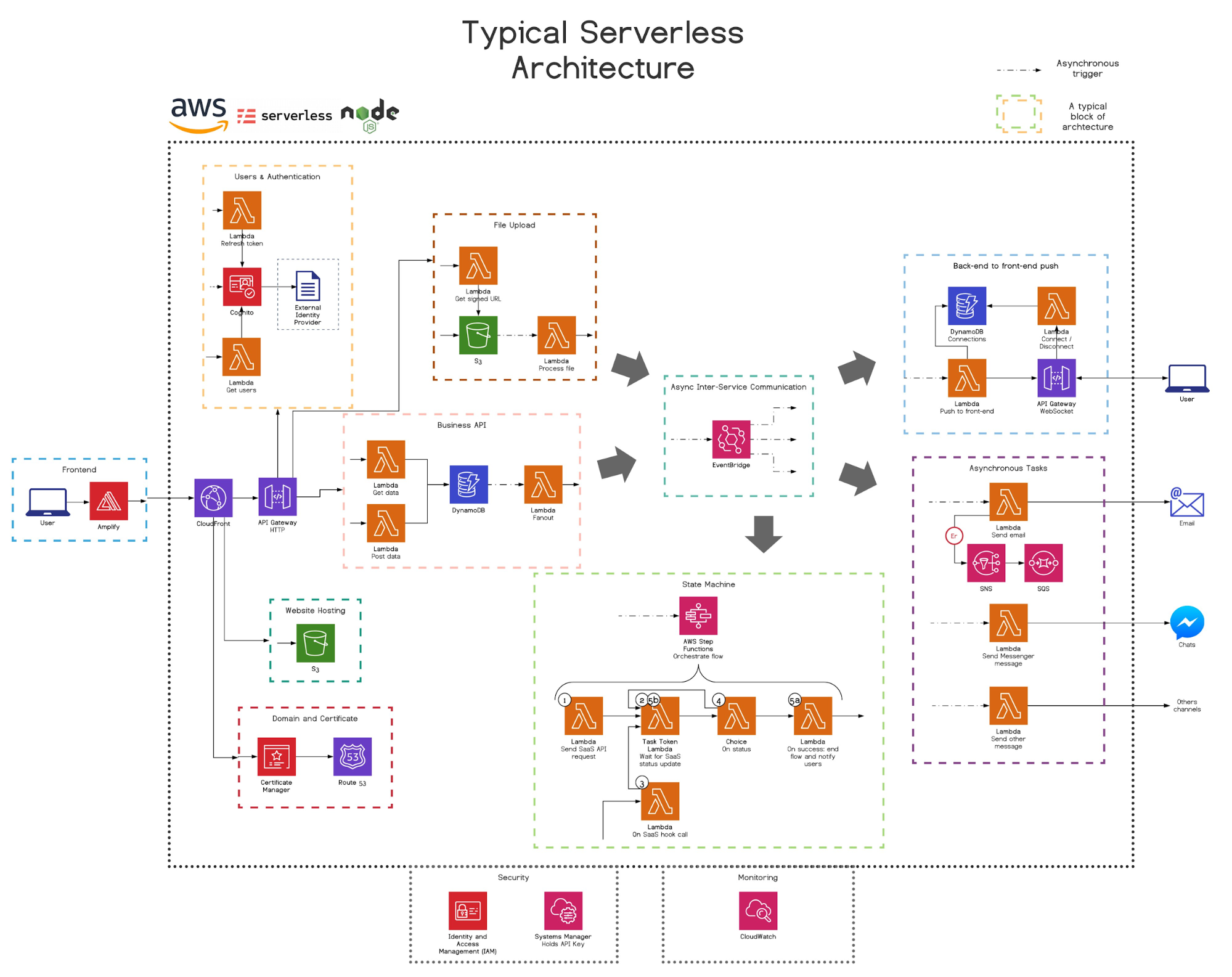
There were some valid points on both sides of the argument if you take the time to read through it.
For the discussion we are about to have, I have taken some time to rework this diagram in a more traditional model, with functional components and connections that are generally handled in code now cleanly modeled within the “application server”.
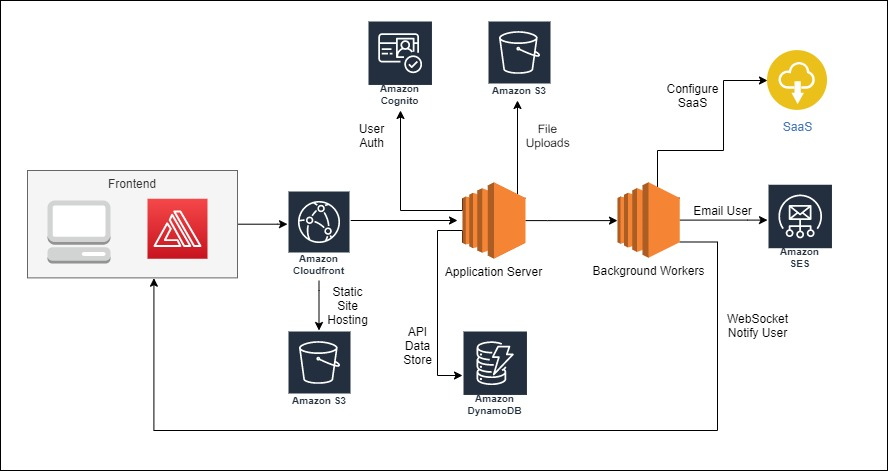
Obviously, I’ve taken the liberty to leave off a few things to simplify this down a bit. However, this reflects fairly close to a diagram I might see coming out of a typical design session. The important capabilities are all still modeled there, you know your core technology and services that will be used and roughly how they are used. Storing data in a DynamoDB table, storing file uploads to S3, emailing a user with SES, etc.
Comparing the two diagrams, the second one sure looks a lot less menacing.
However, behind each of those arrow-ended lines is an implicit stack of code to manage wiring everything together. Looking at this diagram, I couldn’t tell you exactly what the background workers are doing, or how robust the system is. I couldn’t tell you exactly how files are getting uploaded to S3, or what they are being used for.
If we want to rattle pedantic sabers, I could have labeled the lines a bit better or added some ordering for clarity. That misses the point.
When building our application using serverless and cloud-native services, the building blocks we use have greater shared context among individuals; access to a richer vocabulary of pieces. A byproduct of having discrete components means our diagrams communicate intention and purpose with more clarity and less abstraction.
Instead of a single application server, I have single-responsibility lambda functions. Instead of “background workers,” I have state machines via Step Functions. Someone can look at my diagram and gather context that would take a fair amount more intentional effort to produce in the more traditional patterns.
Don’t get me wrong, nobody is saying serverless is easy. You can’t adopt it on a weekend and expect it to pay dividends by Wednesday. Cloud-Native isn’t some savior that will absolve you of all your other poor decisions.
What many of us are saying and I think we are finally figuring out how to, is that serverless helps communicate business complexities in a standardized way. Clear purpose components and services help reduce abstraction, and make it easier to understand what you are trying to build. In addition, you can usually understand where your system will have distinct types of issues (scalability, reliability, security) and architect specifically to address those areas without needing to increase the complexity of all the other parts of the system.
If you think about it, we’ve found the “measure twice, cut once” of the cloud (diagram twice, yaml once?). A little extra time and forethought now, forced by the nature of the services we choose to consume, can save us a lot of time and pain in the near future.

Build an IPv6-to-IPv4 proxy using CloudFront to enable connectivity with IPv4-only AWS services.





