


Serverless
Replacing Amazon S3 Events with Amazon S3 Data Events
How to synthesize an (almost) identical payload using Amazon EventBridge rules.

Mon, 25 Jun 2018
If you’ve spent any time at all in the cloud, you know the pain of mysterious bills and ever-escalating spend. When you’re paying as you go and scaling on demand, exercising control over your infrastructure costs takes more vigilance, not less. As Expedia’s Subbu Allamaraju has correctly pointed out, in the cloud, cost awareness must be part of the engineering culture, not just something assigned to a governance team on the side. For that reason, Trek10’s CloudOps team spends a lot of time thinking about cloud spend and developing tools to help catch problems before they happen.
One thing we’ve learned is that the first step in limiting the size of your AWS bill is to limit the surprise on the bill. That means keeping a close eye out for cost anomalies: changes in the historical consumption pattern of your cloud resources. Obviously, AWS Budgets with its running total of monthly spend is the first place to look, but we’ve found that static thresholds like that become less useful across many accounts and highly dynamic environments. We don’t just want to know how much we’ve spent, but also to mine deeper trends.
Trek10’s CloudOps team looks for cost anomalies in two ways: big spikes and slow changes. We use standard deviation to determine when a spike is “big”, and we calculate the cost change from 7, 21, and 35 days ago to determine if there is a slower-growing change that adds up to a big difference over a longer window of time. (We use multiples of 7 to avoid comparing different days of the week and getting false alarms from systems with large intra-week fluctuations.)
We use the AWS Cost Explorer API (formerly CloudWatch Billing Metrics) to calculate these alerts for our own AWS accounts and for our CloudOps clients.
We define anomalies based on the following thresholds:
If one of these thresholds is breached for more than two days in a row, we create an alert message and send it to Datadog, where we maintain dashboards tracking all the metrics captured by our system. The alerts also integrate automatically with our SLA-enforced ticketing system, so our clients can rest assured that their bills aren’t mushrooming while they sleep.
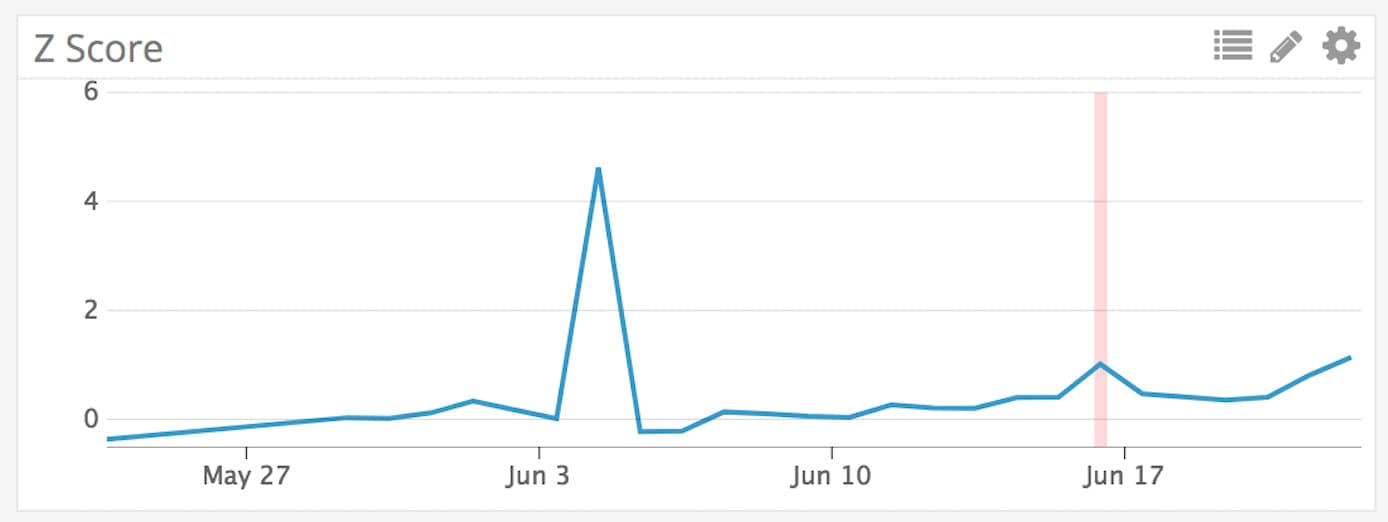
The graph above shows the z-score for one of our internal accounts over the last few days. You’ll notice there’s no red line indicating an alert for that big spike in the graph in early June. That’s because the cost increase did not last long enough to be of concern. The red line later in the month is actually catching a slow-growing change — in this case, because we were accumulating some resources in the account that weren’t getting cleaned up.
Oh, and given our serverless proclivities, you won’t be surprised to learn that all of these checks run in Lambda and incur little to no overhead cost.
Our billing alert system often catches legitimate spend changes that require no further action — for example, when one of our clients starts using a new AWS service. But recently we noticed an alert that seemed a little more concerning.
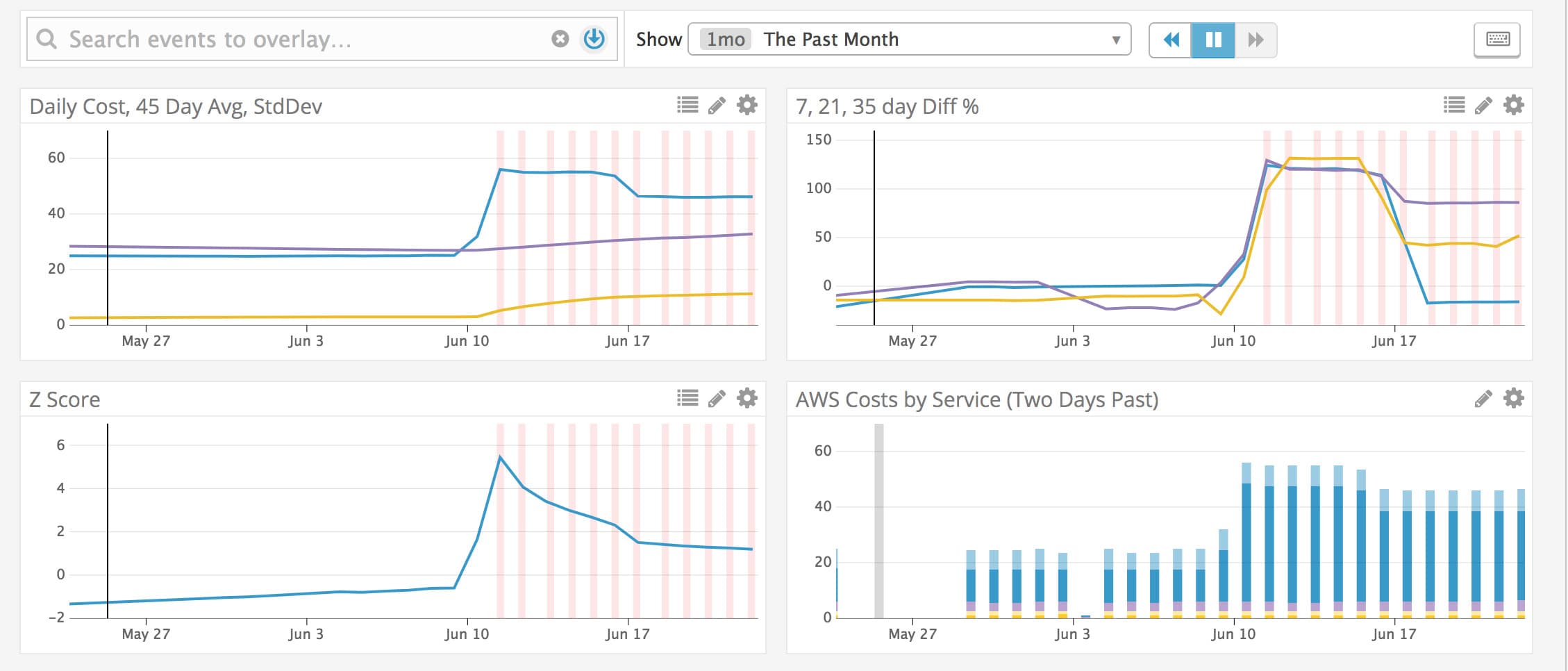
In the graphs above, taken from our Datadog dashboard, you’ll notice a large increase in daily cost around the middle of June. Once the increase had breached our thresholds, our alert system automatically registered an alert and filed a support ticket for our CloudOps team. We followed up with the client to confirm the source of the problem (in this case, expiring reserved instances), and got the reservations renewed. No cloud bills were harmed in the detection of this issue!
Optimizing cloud costs isn’t a one-solution-fits-all problem. It takes attention and discipline from every part of your organization. And taking proactive steps to monitor your environment may expose slower-growing issues that have a big impact over time. If you’re interested in leveraging the Trek10 CloudOps team’s expertise to level up your spend management game, we’d love to hear from you.
Thanks to Trek10’s James Bowyer for contributing to this post.

How to synthesize an (almost) identical payload using Amazon EventBridge rules.






