

Spotlight
AWS Lambda Functions: Return Response and Continue Executing
A how-to guide using the Node.js Lambda runtime.
Tue, 13 Sep 2016
Serverless on AWS represents a new way to architect highly performant, highly resilient, and very low-maintenance cloud-native systems. In this occasional series, we’re going to review some interesting design patterns for Serverless systems on AWS. Hopefully this will give you an idea of what you can build and you can apply these concepts to your own use case. Some of the most interesting Serverless architectures combine several of these patterns into a single system.
If you’d like a more high-level introduction to Serverless, check out this post.
Today, we’ll focus on a relatively simple but very powerful pattern for a wide variety of ETL applications…
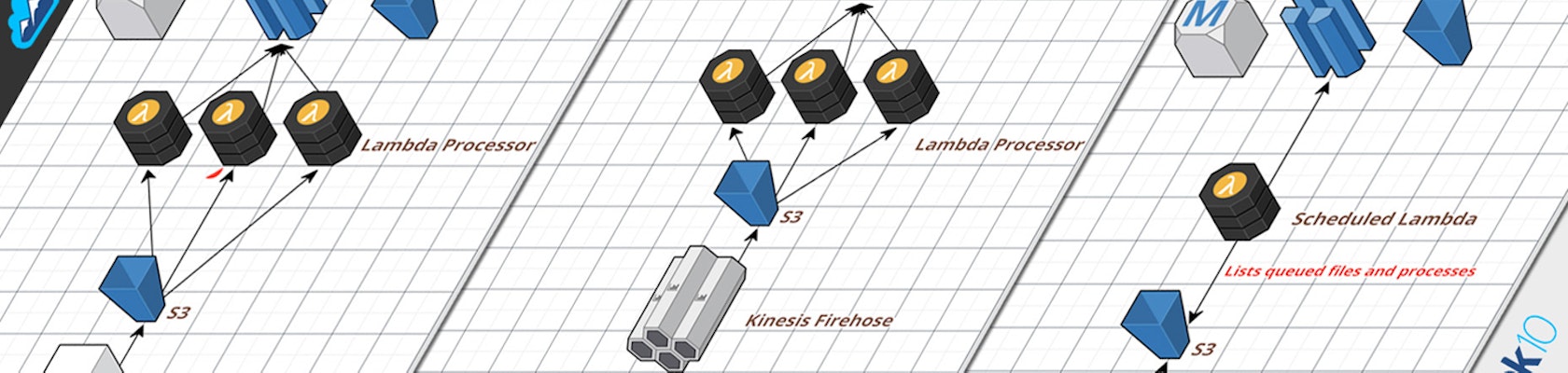
There are many ways to pipeline data from a producer to a final source. S3 and Lambda represent a very simple and low-cost approach that can also be extended to be very powerful. It is NOT appropriate if you need truly real-time visibility, but that’s a relative term. If you can accept delays of perhaps 15-60 seconds, this is a good solution, and it is far simpler than a truly real-time approach that uses Kinesis.
In its most basic form, your data producer (i.e. a web app or client system) pushes data periodically to S3 in some flat file format. This S3 event triggers a Lambda function which processes the data and pushes it into the final destination, such as Redshift, another SQL database, or perhaps back into S3 in some archived form.

The Redshift COPY command, invoked in the Lambda function, is a straightforward and efficient way to load the data into Redshift. AWS outlined this in more detail in this great blog post.
To make this approach more robust, we always make sure to move the files from some /incoming folder in S3 to a /processed folder after a successful load. This makes it easy to identify and reprocess failures, and you can add an S3 Lifecycle rule to the /processed folder to archive or delete the raw data after some period.
Of course, this simple version has some limitations:
We can evolve this basic pattern to solve both of these problems. To solve #1, we simply put Kinesis Firehose in the middle. Kinesis Firehose is a fully managed streaming data queue that handles buffering and batching your data and pushing it into S3. You can push data in via the API, or you can use the Linux agent to continuously monitor a set of files and let the agent handle sending new data to Kinesis.

To solve #2, we need to introduce a centralized queue. There are a few ways to do this. One is the Kinesis Firehose approach we discussed above… because a single system is doing all the buffering and batching, this “many loaders” problem goes away. But this approach may not be ideal. If you need FIFO, you could use an actual queue like SQS (loose FIFO) or Dynamo or Redis. But in most cases, FIFO is not critical, and you can simply use S3 as your queue. The process works like this:
/incoming folder/incoming
If load time is a concern (Lambda has a max timeout of 5 minutes), you could use an initial Lambda function to list the files and then the Lambda Fanout pattern to have individual Lambda functions perform each load in parallel, again tuning for your particular data loading characteristics so you don’t overload your destination.
Stepping back, the bottom line to keep in mind here is that S3 → Lambda → Data source is a simple and powerful method for managing a near-real-time data pipeline. There are several flavors to this approach to fit your use case. But at the end of the day, you have almost unlimited scalability, no computing or storage infrastructure to manage, no complex ETL tools, and very low total cost. So give it a try, or hit us up if you’d like some help!

A how-to guide using the Node.js Lambda runtime.



